I am moving this blog to a new location, now integrated as part of my personal website:
All future posts will be made there instead of here (include a new one that I just posted).

I am moving this blog to a new location, now integrated as part of my personal website:
All future posts will be made there instead of here (include a new one that I just posted).

Ashwin Sah just proved a new upper bound to diagonal Ramsey numbers. See his preprint on the arXiv. This is the first improvement since Conlon’s upper bound published in Annals of Math in 2009, which in turn built on earlier work of Thomason (1988).
Obtaining asymptotics of Ramsey numbers is perhaps the central open problem of Ramsey theory in combinatorics. Research on this problem had led us to a lot of new mathematics that have proven to be useful elsewhere. Most notably, Erdős’ proof of a lower bound to Ramsey numbers (1947) initiated the probabilistic method, by now an indispensable method in combinatorics.
Ashwin’s improvement relies on new insights into graph quasirandomness properties.
Congratulations Ashwin! This is an impressive accomplishment.
Ashwin had just finished his undergraduate studies at MIT. I’m happy that he will be staying at MIT for his PhD. Ashwin already has an impressive list of papers. I had previously mentioned Ashwin on this blog reporting on our joint work (together with Mehtaab Sawhney and David Stoner) on our work on independent sets and the reverse Sidorenko inequality.

I’m happy to announce a new paper titled Joints tightened coauthored with Hung-Hsun Hans Yu, an undergraduate student at MIT. In this paper, we determine the tight constant in the joints problem.

The joints problem is a classic problem in incidence geometry. A typical question in incidence geometry concerns what kinds of configurations can be built using just points and lines.
Suppose you are allowed to draw L lines in space. What is the maximum possible number of points that lie on three lines (let’s call these points “triple intersections” for now)?
It turns out this is not a great question, since you can “cheat” by drawing a 2-dimensional picture from a grid as below. This configuration of L lines has ")


The issue with the above example is that it is really a 2-dimensional configuration, whereas we really want to ask a 3-dimensional question. One way to make the problem much more interesting is only count “truly 3-dimensional” intersection points.
Given a collection of lines in space, we define a joint to be a point that is contained in three of our lines and not all lying on the same plane.

Joints problem. What is the maximum number of joints that can be formed by L lines in 3-dimensional space?
The joints problem was raised in early 1990’s, and it turned out to be a very interesting problem! Besides its intrinsic interest as a combinatorial geometry problem, it also caught the attention of analysts as the joints problem is connected to the Kakeya problem, a central problem in analysis (this connection was popularized by Wolff).
Here are some examples of configurations of lines that have a lot of joints.
Example 1. The easiest example to visualize is by considering a k × k × k grid of lines, which has 
^{3/2}")

Example 2. Actually, there is another example that has even more joints (by a constant factor). Think about a tetrahedron, formed by 4 faces (planes), and whose edges form 6 lines, and the vertices form 4 joints. We can generalize the tetrahedron example by taking k generic planes in space, and have the planes pairwise intersect to make 


In both examples, the number of joints is ")
")
Larry Guth conjectured in his book The Polynomial Methods in Combinatorics that the second example above is best possible. I first learned about this very nice conjecture as a graduate student in Guth’s class on the polynomial method.
The main result of our paper is a new improved upper bound on the joints problem, matching the constant in the second example above. More precisely, we prove that L lines in space make at most 
It was quite unexpected to us that such a tight bound can even be proved, especially given how long it took just to obtain an upper bound of the right order of magnitude on the joints problem. In pretty much all other classical problems in incidence geometry (i.e., the Szemerédi–Trotter theorem), the optimal constant factor is not known. In fact, our result might be the first one in incidence geometry that obtains a tight constant factor.
I’m happy to announce our new paper Equiangular lines with a fixed angle joint with four MIT coauthors: Zilin Jiang, Jonathan Tidor, Yuan Yao, and Shengtong Zhang.

Zilin is an Instructor (postdoc), Jonathan is my PhD student who just finished his second year, and Yuan and Shengtong are undergraduates who just finished their second and first respective years.
Our paper solves a longstanding problem in discrete geometry concerning equiangular lines, which are configurations of lines in space that are pairwise separated by the same angle. How many such lines can exist simultaneously in a given dimension?
We determine, for every fixed angle, the maximum number of equiangular lines with the given angle in high dimensions.
Our paper builds on a long sequence of earlier ideas. There were some important progress on this problem by Igor Balla, Felix Dräxler, Peter Keevash, and Benny Sudakov, as featured in this earlier Quanta Magazine article written for a lay audience.
In the end we finished off the problem in a clean and crisp manner, in a 10-page paper with a self-contained proof.
It has been known that the study of equiangular lines is closed linked to spectral graph theory, which seeks to understand graphs via their spectrum (i.e., eigenvalues). We prove our main result via a new insight in spectral graph theory, namely that a bounded degree graph must have sublinear second eigenvalue multiplicity.
I just finished a new paper, Impartial digraphs, coauthored with Yunkun Zhou, who just completed his undergraduate studies at MIT and will be moving to Stanford to start his PhD this fall.

The problem (along with the conjecture that we proved) was proposed by Jacob Fox, Hao Huang, and Choongbum Lee. Ron Graham had also told me about this problem with much enthusiasm during tea time one afternoon at the Berkeley Simons Institute a couple of years ago, after learning about it from Jacob.
I really enjoyed working on this paper with Yunkun. The problem is natural and simple to state, the answer appears somewhat unexpected (at least initially), and the solution ended up being quite tricky yet clean, employing a variety of tools in combinatorics, ranging from analytic methods (graph limits), algebraic considerations (polynomial identities and factorization), as well basic combinatorial techniques such as bijections.
We are going to talk about directed graphs (which graph theorists like to abbreviate as digraphs). These are graphs where every edge is given an orientation.

A tournament is a directed graph where there is a directed edge between every pair of vertices (think of it as recording the outcome of a round-robin tournament where every player plays against every other player).

Given a directed graph H (think of it as a pattern), we can ask: how many different copies of the pattern H appear in a given tournament?

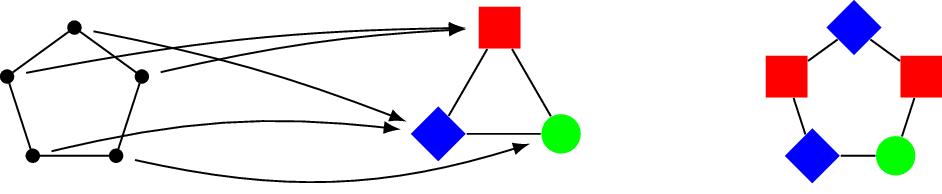
Look at the following 4-vertex tournament H. It has the following curious property: all tournaments of a fixed size contains the same number of copies of H, no matter how the edges in the tournament are oriented.

Hmm, why is this true? And are there other directed graphs H with the same property, namely that all tournaments of a given size contain the same number of copies of H?
In the good old mathematical tradition, we came up with a name for directed graphs H with this curious property: we called them impartial (as in: impartial judges of a tournament).
Okay. So why is the above directed graph impartial? Are there any other impartial directed graphs? What are all the impartial directed graphs?
Here is a simple example of an impartial digraph:

Here is another one:

Indeed, given any 10-vertex tournament, we can count the number of copies of the first edge (it doesn’t depend on the tournament), and then count the number of copies of the second edge among the remaining 8 vertices (it still doesn’t depend on the tournament).
Once these two edges are placed in a tournament, there are two ways to join their tips, but they result in identical patterns (one flipped from the other):

It must then follow that this directed graph is impartial as well:

We can follow the same logic and continue this procedure, iterate, and build up even larger impartial directed graphs. Each step, take two copies of the previous tree (keeping the same edge orientations), and then add a new edge between a twin pair of vertices.




We call any directed graph that can building up as above a recursively bridge-mirrored tree.
The same argument as earlier shows that every recursively bridge-mirrored tree is impartial.
Are there other impartial digraphs? Did we miss any?
It turns out, there are actually no others. We have found them all, and that is the main result of our paper:
Theorem. A directed graph is impartial if and only if every component is recursively bridge-mirrored trees.
Just a word about how about this problem is related to a bigger picture. It is related to a number of other graph homomorphism inequalities that are central in extremal graph theory. It can be considered as the “equality case” for a directed analog of an open problem known as Sidorenko’s conjecture. See our paper for some further discussions and open problems.
Together with undergraduates Ashwin Sah, Mehtaab Sawhney, and David Stoner (the same team that proved Kahn’s conjecture on independent sets that I blogged about earlier), we are excited to announce our new paper A reverse Sidorenko inequality. This paper solves several open problems concerning graph colorings and homomorphisms, including one of my favorite problems regarding maximizing the number of q-colorings in a d-regular graph. I had previously blogged about some of these problems.
It has been truly a pleasure working with Ashwin, Mehtaab, and David on this project. I have learned so much from them.
Here are some highlights of our new results.
1. Graph colorings. Among d-regular graphs, which graph has the most number of proper q-colorings, exponentially normalized by the number of vertices of G?
We show that the extremal graph is the complete bipartite graph Kd,d (or disjoint unions thereof, as taking disjoint copies does not change the quantity due to the normalization).
2. Graph homomorphisms. Among d-regular graphs, which triangle-free graph G has the most number of homomorphisms into a fixed H, again exponentially normalized by the number of vertices of G?
We show that the extremal graph G is the complete bipartite graph Kd,d.
The triangle-free hypothesis on G is best possible in general. For certain specific H, such as Kq, corresponding to proper q-colorings as earlier, the triangle-free hypothesis can be dropped. It remains a wide open problem to determine for which H can one drop the triangle-free hypothesis on G.
3. Partition functions of Ferromagnetic spin models. Among d-regular graphs, which graph maximizes the log-partition function per vertex of a given Ferromagnetic spin model (e.g., Ising model)?
We show that the extremal graph is the clique Kd+1.
For each setting, we establish our results more generally for irregular graphs as well, similar to our earlier work on independent sets.
Our results can be interpreted as a reverse form of the inequality in Sidorenko’s conjecture, an important open problem in graph theory stating a certain positive correlation on two-variable functions.
One can also view our results as a graphical analog of the Brascamp-Lieb inequalities, a central result in analysis.
This paper resolves one of my favorite open problems on this topic (the number of graph colorings). It also points us to many other open problems. Let me conclude by highlighting one of them (mentioned in #2 earlier). I’ll state it in a simpler form for d-regular graphs, but it can be stated more generally as well.
Open problem. Classify all H with the following property: among d-regular graphs G, the number of homomorphisms from G to H, exponentially normalized by the number of vertices of G, is maximized by G = Kd,d.
Our results show that H = Kq works, even when some of its vertices are looped. Generalizing this case, we conjecture that all antiferromagnetic models H have the same property (though we know that this would not be the complete class, even if true).
I am excited to announce our new paper, The number of independent sets in an irregular graph, coauthored with these three amazing collaborators:



Ashwin is a freshman at MIT, Mehtaab is a sophomore at MIT, and David is a junior at Harvard.
The paper solves a conjecture made by Jeff Kahn in 2001 concerning the number of independent sets in a graph.
An independent set of a graph is a subset of vertices with no two adjacent. For example, here is the complete list of independent sets of a cycle of length 4:

Since many problems in combinatorics can be naturally phrased in terms of independent sets in a graph or hypergraph, getting good bounds on the number of independent sets is a problem of central importance.
Instead of giving the exact statement of the conjecture (now theorem), which you can find in the abstract of our paper, let me highlight a specific instance of a problem addressed by the theorem:
Consider the family of graphs with no isolated vertices and
- exactly a third of the edges have degree 3 on both endpoints, and
- a third of the edges have degree 4 on both endpoints,
- the remaining third of the edges have degree 3 on one endpoint and degree 4 on the other endpoint.
What is the smallest constant
such that every
-vertex graph satisfying the above properties has at most
independent sets?
In other words, letting
denote the number of independent sets and
the number of vertices of
, maximize the quantity
over all graphs
(See the end of this post for the answer)
In summer 2009, as an undergraduate participating in the wonderful Research Experience for Undergraduates (REU) run by Joe Gallian in Duluth, MN, I learned about Kahn’s conjecture (somewhat accidentally actually, as I was working on a different problem that eventually needed some bounds on the number of independent sets, and so I looked up the literature and learned, slightly frustratingly at the time, that it was an open problem). It was on this problem that I had written one of my very first math research papers.
I had been thinking about this problem on and off since then. A couple years ago, Joe Gallian invited me to write an article for a special issue of the American Mathematical Monthly dedicated to undergraduate research (see my previous blog post on this article), where I described old and new developments on the problem and collected a long list of open problems and conjectures on the topic (one of them being Kahn’s conjecture).
This spring, I had the privilege with working with Ashwin, Mehtaab, and David, three energetic and fearless undergraduate students, finally turning Kahn’s conjecture into a theorem. Fearless indeed, as our proof ended up involving quite a formidable amount of computation (especially for such an innocent looking problem), and my three coauthors deserve credit for doing the heavy-lifting. I’ve been told that there had been many late night marathon sessions in an MIT Building 2 classroom where they tore apart one inequality after another.
This is certainly not the end of the story, as many more interesting problems on the subject remain unsolved—my favorite one being the analogous problem for colorings, e.g., instead of counting the number of independent sets, how about we count the number of ways to color the vertices of the graph with 3 colors so that no two adjacent vertices receive the same color? (See my previous blog post for some more discussion.)
Anyway, here is the the answer to the question above. The number of independent sets in an 
This post is adapted from my new expository survey Extremal regular graphs: independent sets and graph homomorphisms.
The earliest result in extremal graph theory is usually credited to Mantel, who proved, in 1907, that a graph on 
We seem to know less about sparse graphs (a general mantra in combinatorics, it seems). Let us focus on 
An independent set in a graph is a subset of vertices with no two adjacent. Many combinatorial problems can be reformulated in terms of independent sets by setting up a graph where edges represent forbidden relations.
Question. In the family of
This question was raised by Andrew Granville in the 1988 Number Theory Conference at Banff, in an effort to resolve a problem in combinatorial number theory, namely the Cameron–-Erdős conjecture on the number of sum-free sets. The question appeared first in print in a paper by Noga Alon, who proved an asymptotic upper bound and speculated that, at least when 

Some ten years later, Jeff Kahn arrived at the same conjecture while studying a problem arising from statistical physics. Using a beautiful entropy argument, Kahn proved the conjecture under the additional assumption that the graph is already bipartite.
Fast forward another nearly ten years. In the summer of 2009, during my last summer as an undergraduate, I spent a fun and productive summer attending Joe Gallian’s REU in Duluth, MN (a fantastic program, by the way!), and there I showed that Kahn’s theorem can be extended to all regular graphs, not just bipartite ones.
Here is the theorem statement. We write }")
 := |I(G)|}")
Theorem (Kahn, Z.) If
 \le i(K_{d,d})^{n/(2d)} = (2^{d+1} - 1)^{n/(2d)}")
In the survey, I provide an exposition of the proofs of these two theorems as well as a discussion of subsequent developments. Notably, Davies, Jenssen, Perkins, and Roberts recently gave a brand new proof of the above theorems by introducing a powerful new technique, called the occupancy method, inspired by ideas in statistical physics, and it already has a number of surprising new consequences.
On a personal level, I am pleased to see this topic gaining renewed interest. (Also, somewhat to my chagrin, my undergraduate paper, according to Google Scholar, still remains my most cited paper to date.)
I shall close this blog post with one of my favorite open problems in this area.
Let }")

Conjecture. If 
 \le c_q(K_{d,d})^{n/(2d)}")
I was pleased to learn from Will Perkins, who gave a talk at Oxford last week, that he, along with Davies, Jenssen, and Roberts, recently proved the conjecture for 3-regular graphs. The proof uses the occupancy method that they developed earlier. The method is reminiscent of the flag algebra machinery developed by Razborov some ten years ago for solving extremal problems in dense graphs. The new method can be seen as some kind of “flag algebra for sparse graphs”. I find this development quite exciting, and I expect that more news will come.
Eyal Lubetzky and I just finished and uploaded to the arXiv our new paper On the variational problem for upper tails of triangle counts in sparse random graphs. This paper concerns the following question:
The upper tail problem for triangles. What is the probability that the number of triangles in an Erdős-Rényi graph graph 

This problem has a fairly rich history, and it is considered a difficult problem in probabilistic combinatorics. In a 2002 paper titled The infamous upper tail, Janson and Ruciński surveyed the progress on the problem and described its challenges (they also considered the upper tail problem more generally for any subgraph 
Here we consider the case when p tends to zero as n grows (the dense case, where 

)n^2p^2}}")
)\binom{n}{3} p^3}")

Let t(G) denote the triangle density in a graph G, i.e., the number of triangles in G as a fraction of the maximum possible number 
Is this lower bound tight? That is, can we find a matching upper bound for the upper tail probability? This is precisely the infamous upper tail problem mentioned earlier. For a long time there was no satisfactory upper bound anywhere close to the lower bound. A breakthrough by Kim and Vu in 2004 gave an upper bound of the form }")
}")
Now we know the correct order in the exponent, what remains unknown is the constant in front of the 

Eyal and I have been working on this variational problem for quite some time, starting with our previous paper where we studied the problem in the dense setting (constant 

where we determine the constant in the exponent to be
We described earlier the story behind the 




} = p^{(\delta/3 + o(1))n^2p^2}}")


There has quite a bit of activities around the Green-Tao theorem recently. In this blog post, I want to highlight some of these developments, focusing on the following papers, which were all posted on the arXiv in the past couple of months.
Relative Szemerédi theorem
Multidimensional Szemerédi theorem in the primes
——–
We start the story with Szemerédi’s famous result.
Szemerédi’s theorem. Every subset of integers with positive density contains arbitrarily long arithmetic progressions.
Green and Tao proved their famous theorem extending Szemerédi’s theorem to the primes.
Green-Tao theorem. The primes contain arbitrarily long arithmetic progressions. In fact, any subset of the primes with positive relative density contains arbitrarily long arithmetic progressions.
An important idea in Green and Tao’s work is the transference principle. They transfer Szemerédi’s theorem as a black box to the sparse setting, so that it can be applied to subsets of a sparse pseudorandom set of integers (in this case, some carefully designed enveloping set for the primes).

Jacob Fox, David Conlon, and me at the Erdős Centennial conference in Budapest, Hungary, July 2013.
In my recent paper with David Conlon and Jacob Fox, we gave a new simplified approach to proving the Green-Tao theorem. In particular, we established a new relative Szemerédi theorem, which required simpler pseudorandomness hypotheses compared to Green and Tao’s original proof. Roughly speaking, a relative Szemerédi theorem is a result of the following form.
Relative Szemerédi theorem (roughly speaking). Let S be a pseudorandom subset of integers. Then any subset of S with positive relative density contains long arithmetic progressions.
The original proof in our paper followed the hypergraph approach, and in particular used the hypergraph removal lemma, a deep combinatorial result, as a black box. Subsequently, I wrote up a short six-page note showing how to prove the same result by directly transferring Szemerédi’s theorem, without going through hypergraph removal lemma. The former approach is more powerful and more general, while the latter approach is more direct and gives better quantitative bounds.
Next we shift our attention to higher dimensions. Furstenberg and Katznelson proved, using ergodic-theoretic techniques, a multidimensional generalization of Szemerédi’s theorem.
Multidimensional Szemerédi theorem (Furstenberg and Katznelson). Any subset of Zd with positive density contains arbitrary constellations.
Here a constellation means some finite set R of lattice points, and the theorem says that the subset of Zd contains some translation of a dilation of R.
(This result always reminds me of a lovely scene in the movie A Beautiful Mind where the John Nash character traces out shapes among the stars.)

“Pick a shape” – A Beautiful Mind
Tao proved a beautiful extension for the Gaussian primes.
Theorem (Tao). The Gaussian primes contain arbitrary constellations.
In that paper, Tao also made the following interesting conjecture: let P denote the primes. Then any subset of P × P of positive relative density contains arbitrary constellations. This statement can be viewed as a hybrid of the Green-Tao theorem and the multidimensional Szemerédi theorem. Recently this conjecture was resolved by Tao and Ziegler, and independently by Cook, Magyar, and Titichetrakun.
Multidimensional Szemerédi theorem in the primes. Let P denote the primes. Then any subset of Pd with positive density contains arbitrary constellations.
Terry Tao has written a blog post about this new result where he describes the ideas in the proofs (so I won’t repeat too much). Tao and Ziegler proved their result via ergodic theory. Their proof is about 19 pages long, and they assume as black boxes two powerful results: (1) Furstenberg and Katznelson’s multidimensional Szemerédi theorem (more precisely their equivalent ergodic-theoretic formulation) and (2) the landmark results of Green, Tao, and Ziegler on linear equations in primes (and related work on the Mobius-nilsequences conjecture and the inverse conjecture on the Gowers norm). Both these results are deep and powerful hammers.
In contrast, Cook, Magyar, and Titichetrakun proceeded differently as they develop a sparse extension of hypergraph regularity method from scratch, without assuming previous deep results. Though their paper is much longer, at 44 pages.
In a recent paper by Jacob Fox and myself, we give a new and very short proof of the same result, assuming the same tools as the Tao-Ziegler proof. Our paper is only 4 pages long, and it uses a very simple sampling argument described in two paragraphs on the first page of our paper (all the ideas are on the first page; the rest of the paper just contains the technical details spelled out). I invite you to read the first page of our paper to learn the very short proof of the theorem.
 \geq (1 + \delta)p^3) \geq \exp\Big(-(\tfrac12 \delta^{2/3} +o(1))n^2 p^2 \log(1/p)\Big).")
 \geq 1 + \delta) = \exp\Big(-(C_\delta+o(1))n^2 p^2 \log(1/p)\Big).")

