Recent entries
Weeknotes: Embeddings, more embeddings and Datasette Cloud four days ago
Since my last weeknotes, a flurry of activity. LLM has embeddings support now, and Datasette Cloud has driven some major improvements to the wider Datasette ecosystem.
Embeddings in LLM
LLM gained embedding support in version 0.9, and then got binary embedding support (for CLIP) in version 0.10. I wrote about those releases in detail in:
- LLM now provides tools for working with embeddings
- Build an image search engine with llm-clip, chat with models with llm chat
Embeddings are a fascinating tool. If you haven’t got your head around them yet the first of my blog entries tries to explain why they are so interesting.
There’s a lot more I want to built on top of embeddings—most notably, LLM (or Datasette, or likely a combination of the two) will be growing support for Retrieval Augmented Generation on top of the LLM embedding mechanism.
Annotated releases
I always include a list of new releases in my weeknotes. This time I’m going to use those to illustrate the themes I’ve been working on.
The first group of release relates to LLM and its embedding support. LLM 0.10 extended that support:
-
llm 0.10—2023-09-12
Access large language models from the command-line
Embedding models can now be built as LLM plugins. I’ve released two of those so far:
-
llm-sentence-transformers 0.1.2—2023-09-13
LLM plugin for embeddings using sentence-transformers -
llm-clip 0.1—2023-09-12
Generate embeddings for images and text using CLIP with LLM
The CLIP one is particularly fun, because it genuinely allows you to build a sophisticated image search engine that runs entirely on your own computer!
-
symbex 1.4—2023-09-05
Find the Python code for specified symbols
Symbex is my tool for extracting symbols—functions, methods and classes—from Python code. I introduced that in Symbex: search Python code for functions and classes, then pipe them into a LLM.
Symbex 1.4 adds a tiny but impactful feature: it can now output a list of symbols as JSON, CSV or TSV. These output formats are designed to be compatible with the new llm embed-multi command, which means you can easily create embeddings for all of your functions:
symbex '*' '*:*' --nl | \
llm embed-multi symbols - \
--format nl --database embeddings.db --storeI haven’t fully explored what this enables yet, but it should mean that both related functions and semantic function search (“Find my a function that downloads a CSV”) are now easy to build.
-
llm-cluster 0.2—2023-09-04
LLM plugin for clustering embeddings
Yet another thing you can do with embeddings is use them to find clusters of related items.
The neatest feature of llm-cluster is that you can ask it to generate names for these clusters by sending the names of the items in each cluster through another language model, something like this:
llm cluster issues 10 \
-d issues.db \
--summary \
--prompt 'Short, concise title for this cluster of related documents'One last embedding related project: datasette-llm-embed is a tiny plugin that adds a select llm_embed('sentence-transformers/all-mpnet-base-v2', 'This is some text') SQL function. I built it to support quickly prototyping embedding-related ideas in Datasette.
-
datasette-llm-embed 0.1a0—2023-09-08
Datasette plugin adding a llm_embed(model_id, text) SQL function
Spending time with embedding models has lead me to spend more time with Hugging Face. I realized last week that the Hugging Face all models sorted by downloads page doubles as a list of the models that are most likely to be easy to use.
One of the models I tried out was Salesforce BLIP, an astonishing model that can genuinely produce usable captions for images.
It’s really easy to work with. I ended up building this tiny little CLI tool that wraps the model:
-
blip-caption 0.1—2023-09-10
Generate captions for images with Salesforce BLIP
Releases driven by Datasette Cloud
Datasette Cloud continues to drive improvements to the wider Datasette ecosystem as a whole.
It runs on the latest Datasette 1.0 alpha series, taking advantage of the JSON write API.
This also means that it’s been highlighting breaking changes in 1.0 that have caused old plugins to break, either subtly or completely.
This has driven a bunch of new plugin releases. Some of these are compatible with both 0.x and 1.x—the ones that only work with the 1.x alphas are themselves marked as alpha releases.
-
datasette-export-notebook 1.0.1—2023-09-15
Datasette plugin providing instructions for exporting data to Jupyter or Observable -
datasette-cluster-map 0.18a0—2023-09-11
Datasette plugin that shows a map for any data with latitude/longitude columns -
datasette-graphql 3.0a0—2023-09-07
Datasette plugin providing an automatic GraphQL API for your SQLite databases
Datasette Cloud’s API works using database-backed access tokens, to ensure users can revoke tokens if they need to (something that’s not easily done with purely signed tokens) and that each token can record when it was most recently used.
I’ve been building that into the existing datasette-auth-tokens plugin:
-
datasette-auth-tokens 0.4a3—2023-08-31
Datasette plugin for authenticating access using API tokens
Alex Garcia has been working with me building out features for Datasette Cloud, generously sponsored by Fly.io.
We’re beginning to build out social features for Datasette Cloud—feature that will help teams privately collaborate on data investigations together.
Alex has been building datasette-short-links as an experimental link shortener. In building that, we realized that we needed a mechanism for resolving actor IDs displayed in a list (e.g. this link created by X) to their actual names.
Datasette doesn’t dictate the shape of actor representations, and there’s no guarantee that actors would be represented in a predictable table.
So... we needed a new plugin hook. I released Datasette 1.06a with a new hook, actors_from_ids(actor_ids), which can be used to answer the question “who are the actors represented by these IDs”.
Alex is using this in datasette-short-links, and I built two plugins to work with the new hook as well:
-
datasette 1.0a6—2023-09-08
An open source multi-tool for exploring and publishing data -
datasette-debug-actors-from-ids 0.1a1—2023-09-08
Datasette plugin for trying out the actors_from_ids hook -
datasette-remote-actors 0.1a1—2023-09-08
Datasette plugin for fetching details of actors from a remote endpoint
Datasette Cloud lets users insert, edit and delete rows from their tables, using the plugin Alex built called datasette-write-ui which he introduced on the Datasette Cloud blog.
This inspired me to finally put out a fresh release of datasette-edit-schema—the plugin which provides the ability to edit table schemas—adding and removing columns, changing column types, even altering the order columns are stored in the table.
datasette-edit-schema 0.6 is a major release, with three significant new features:
- You can now create a brand new table from scratch!
- You can edit the table’s primary key
- You can modify the foreign key constraints on the table
Those last two became important when I realized that Datasette’s API is much more interesting if there are foreign key relationships to follow.
Combine that with datasette-write-ui and Datasette Cloud now has a full set of features for building, populating and editing tables—backed by a comprehensive JSON API.
-
sqlite-migrate 0.1a2—2023-09-03
A simple database migration system for SQLite, based on sqlite-utils
sqlite-migrate is still marked as an alpha, but won’t be for much longer: it’s my attempt at a migration system for SQLite, inspired by Django migrations but with a less sophisticated set of features.
I’m using it in LLM now to manage the schema used to store embeddings, and it’s beginning to show up in some Datasette plugins as well. I’ll be promoting this to non-alpha status pretty soon.
-
sqlite-utils 3.35.1—2023-09-09
Python CLI utility and library for manipulating SQLite databases
A tiny fix in this, which with hindsight was less impactful than I thought.
I spotted a bug on Datasette Cloud when I configured full-text search on a column, then edited the schema and found that searches no longer returned the correct results.
It turned out the rowid column in SQLite was being rewritten by calls to the sqlite-utils table.transform() method. FTS records are related to their underlying row by rowid, so this was breaking search!
I pushed out a fix for this in 3.35.1. But then... I learned that rowid in SQLite has always been unstable—they are rewritten any time someone VACUUMs a table!
I’ve been designing future features for Datasette that assume that rowid is a useful stable identifier for a row. This clearly isn’t going to work! I’m still thinking through the consequences of it, but I think there may be Datasette features (like the ability to comment on a row) that will only work for tables with a proper foreign key.
sqlite-chronicle
-
sqlite-chronicle 0.1—2023-09-11
Use triggers to track when rows in a SQLite table were updated or deleted
This is very early, but I’m excited about the direction it’s going in.
I keep on finding problems where I want to be able to synchronize various processes with the data in a table.
I built sqlite-history a few months ago, which uses SQLite triggers to create a full copy of the updated data every time a row in a table is edited.
That’s a pretty heavy-weight solution. What if there was something lighter that could achieve a lot of the same goals?
sqlite-chronicle uses triggers to instead create what I’m calling a “chronicle table”. This is a shadow table that records, for every row in the main table, four integer values:
-
added_ms—the timestamp in milliseconds when the row was added -
updated_ms—the timestamp in milliseconds when the row was last updated -
version—a constantly incrementing version number, global across the entire table -
deleted—set to1if the row has been deleted
Just storing four integers (plus copies of the primary key) makes this a pretty tiny table, and hopefully one that’s cheap to update via triggers.
But... having this table enables some pretty interesting things—because external processes can track the last version number that they saw and use it to see just which rows have been inserted and updated since that point.
I gave a talk at DjangoCon a few years ago called the denormalized query engine pattern, describing the challenge of syncing an external search index like Elasticsearch with data held in a relational database.
These chronicle tables can solve that problem, and can be applied to a whole host of other problems too. So far I’m thinking about the following:
- Publishing SQLite databases up to Datasette, sending only the rows that have changed since the last sync. I wrote a prototype that does this and it seems to work very well.
- Copying a table from Datasette Cloud to other places—a desktop copy, or another instance, or even into an alternative database such as PostgreSQL or MySQL, in a way that only copies and deletes rows that have changed.
- Saved search alerts: run a SQL query against just rows that were modified since the last time that query ran, then send alerts if any rows are matched.
- Showing users a note that “34 rows in this table have changed since your last visit”, then displaying those rows.
I’m sure there are many more applications for this. I’m looking forward to finding out what they are!
-
sqlite-utils-move-tables 0.1—2023-09-01
sqlite-utils plugin adding a move-tables command
I needed to fix a bug in Datasette Cloud by moving a table from one database to another... so I built a little plugin for sqlite-utils that adds a sqlite-utils move-tables origin.db destination.db tablename command. I love being able to build single-use features as plugins like this.
And some TILs
This was a fun TIL exercising the new embeddings feature in LLM. I used Django SQL Dashboardto break up my blog entries into paragraphs and exported those as CSV which could then be piped into llm embed-multi, then used that to build a CLI-driven semantic search engine for my blog.
llama-cpp has grammars now, which enable you to control the exact output format of the LLM. I’m optimistic that these could be used to implement an equivalent to OpenAI Functions on top of Llama 2 and similar models. So far I’ve just got them to output arrays of JSON objects.
I’m using this trick a lot at the moment. I have API access to Claude now, which has a 100,000 token context limit (GPT-4 is just 8,000 by default). That’s enough to summarize 100+ comment threads from Hacker News, for which I’m now using this prompt:
Summarize the themes of the opinions expressed here, including quotes (with author attribution) where appropriate.
The quotes part has been working really well—it turns out summaries of themes with illustrative quotes are much more interesting, and so far my spot checks haven’t found any that were hallucinated.
- Trying out cr-sqlite on macOS—2023-09-13
cr-sqlite adds full CRDTs to SQLite, which should enable multiple databases to accept writes independently and then seamlessly merge them together. It’s a very exciting capability!
- Running Datasette on Hugging Face Spaces—2023-09-08
It turns out Hugging Faces offer free scale-to-zero hosting for demos that run in Docker containers on machines with a full 16GB of RAM! I’m used to optimizing Datasette for tiny 256MB containers, so having this much memory available is a real treat.
And the rest:
Build an image search engine with llm-clip, chat with models with llm chat eight days ago
LLM is my combination CLI tool and Python library for working with Large Language Models. I just released LLM 0.10 with two significant new features: embedding support for binary files and the llm chat command.
Image search by embedding images with CLIP
I wrote about LLM’s support for embeddings (including what those are and why they’re interesting) when I released 0.9 last week.
That initial release could only handle embeddings of text—great for things like building semantic search and finding related content, but not capable of handling other types of data.
It turns out there are some really interesting embedding models for working with binary data. Top of the list for me is CLIP, released by OpenAI in January 2021.
CLIP has a really impressive trick up its sleeve: it can embed both text and images into the same vector space.
This means you can create an index for a collection of photos, each placed somewhere in 512-dimensional space. Then you can take a text string—like “happy dog”—and embed that into the same space. The images that are closest to that location will be the ones that contain happy dogs!
My llm-clip plugin provides the CLIP model, loaded via SentenceTransformers. You can install and run it like this:
llm install llm-clip
llm embed-multi photos --files photos/ '*.jpg' --binary -m clipThis will install the llm-clip plugin, then use embed-multi to embed all of the JPEG files in the photos/ directory using the clip model.
The resulting embedding vectors are stored in an embedding collection called photos. This defaults to going in the embeddings.db SQLite database managed by LLM, or you can add -d photos.db to store it in a separate database instead.
Then you can run text similarity searches against that collection using llm similar:
llm similar photos -c 'raccoon'I get back:
{"id": "IMG_4801.jpeg", "score": 0.28125139257127457, "content": null, "metadata": null}
{"id": "IMG_4656.jpeg", "score": 0.26626441704164294, "content": null, "metadata": null}
{"id": "IMG_2944.jpeg", "score": 0.2647445926996852, "content": null, "metadata": null}
And sure enough, IMG_4801.jpeg is this:

(I was pretty excited to snap a photo of a trash panda in an actual trash can.)
CLIP is a pretty old model at this point, and there are plenty of interesting alternatives that are just waiting for someone to wrap them in a plugin. I’m particularly excited about Facebook’s ImageBind, which can embed images, text, audio, depth, thermal, and IMU data all in the same vector space!
Chat with models using llm chat
The other big feature in LLM 0.10 is the new llm chat command.
Prior to this release, the way to have an ongoing conversation with a model was through the -c/--continue flag. You could start a conversation like this:
llm -m gpt-4 'Help me understand generators in Python'Then ask a follow-up question using -c like so:
llm -c 'Show me an example involving the cast of Riverdale'This works well, and everything gets logged to SQLite so you can run llm logs -c to see a full log of your most recent conversation.
You could continue a past conversation as well, using llm --cid ID to specify the conversation ID, recorded in those logs.
There was one big problem though: LLM plugins allow you to install models on your own machine, but a conversation with them that spans multiple command invocations resulted in that model being loaded into memory and then un-loaded again for every prompt.
The new llm chat solves that. You can now run llm chat -m model_id to start an interactive chat in your terminal with your model of choice.
Here’s an example using Llama 2 13B, installed via the llm-mlc plugin.
llm chat -m mlc-chat-Llama-2-13b-chat-hf-q4f16_1You can set an alias for the model to make that easier to remember.
Here’s an example chat session with Llama 2:
Type 'exit' or 'quit' to exit
Type '!multi' to enter multiple lines, then '!end' to finish
> Who are you?
Hello! I'm just an AI, here to assist you with any questions you may have.
My name is LLaMA, and I'm a large language model trained to provide helpful
and informative responses to a wide range of questions and topics. I'm here
to help you find the information you need, while ensuring a safe and
respectful conversation. Please feel free to ask me anything, and I'll do my
best to provide a helpful and accurate response.
> Tell me a joke about otters
Sure, here's a joke about otters:
Why did the otter go to the party?
Because he heard it was a "whale" of a time!
(Get it? Whale, like a big sea mammal, but also a "wild" or "fun" time.
Otters are known for their playful and social nature, so it's a lighthearted
and silly joke.)
I hope that brought a smile to your face! Do you have any other questions or
topics you'd like to discuss?
> exit
I like how Llama 2 enthusiastically explains its own jokes! This is a great demonstration of why techniques like RLHF are so important—you need to go way beyond a raw language model if you’re going to teach one not to be this corny.
Each line of your chat will be executed as soon as you hit <enter>. Sometimes you might need to enter a multi-line prompt, for example if you need to paste in an error message. You can do that using the !multi token, like this:
llm chat -m gpt-4Chatting with gpt-4
Type 'exit' or 'quit' to exit
Type '!multi' to enter multiple lines, then '!end' to finish
> !multi custom-end
Explain this error:
File "/opt/homebrew/Caskroom/miniconda/base/lib/python3.10/urllib/request.py", line 1391, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "/opt/homebrew/Caskroom/miniconda/base/lib/python3.10/urllib/request.py", line 1351, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 8] nodename nor servname provided, or not known>
!end custom-end
llm chat also supports system prompts and templates. If you want to chat with a sentient cheesecake, try this:
llm chat -m gpt-3.5-turbo --system '
You are a stereotypical sentient cheesecake with strong opinions
who always talks about cheesecake'You can save those as templates too:
llm --system 'You are a stereotypical sentient cheesecake with
strong opinions who always talks about cheesecake' --save cheesecake -m gpt-4
llm chat -t cheesecakeFor more options, see the llm chat documentation.
Get involved
My ambition for LLM is for it to provide the easiest way to try out new models, both full-sized Large Language Models and now embedding models such as CLIP.
I’m not going to write all of these plugins myself!
If you want to help out, please come and say hi in the #llm Discord channel.
LLM now provides tools for working with embeddings 16 days ago
LLM is my Python library and command-line tool for working with language models. I just released LLM 0.9 with a new set of features that extend LLM to provide tools for working with embeddings.
This is a long post with a lot of theory and background. If you already know what embeddings are, here’s a TLDR you can try out straight away:
# Install LLM
pip install llm
# If you already installed via Homebrew/pipx you can upgrade like this:
llm install -U llm
# Install the llm-sentence-transformers plugin
llm install llm-sentence-transformers
# Install the all-MiniLM-L6-v2 embedding model
llm sentence-transformers register all-MiniLM-L6-v2
# Generate and store embeddings for every README.md in your home directory, recursively
llm embed-multi readmes \
--model sentence-transformers/all-MiniLM-L6-v2 \
--files ~/ '**/README.md'
# Add --store to store the text content as well
# Run a similarity search for "sqlite" against those embeddings
llm similar readmes -c sqliteFor everyone else, read on and the above example should hopefully all make sense.
Embeddings
Embeddings are a fascinating concept within the larger world of language models.
I explained embeddings in my recent talk, Making Large Language Models work for you. The relevant section of the slides and transcript is here, or you can jump to that section on YouTube.
An embedding model lets you take a string of text—a word, sentence, paragraph or even a whole document—and turn that into an array of floating point numbers called an embedding vector.

A model will always produce the same length of array—1,536 numbers for the OpenAI embedding model, 384 for all-MiniLM-L6-v2—but the array itself is inscrutable. What are you meant to do with it?
The answer is that you can compare them. I like to think of an embedding vector as a location in 1,536-dimensional space. The distance between two vectors is a measure of how semantically similar they are in meaning, at least according to the model that produced them.

“One happy dog” and “A playful hound” will end up close together, even though they don’t share any keywords. The embedding vector represents the language model’s interpretation of the meaning of the text.
Things you can do with embeddings include:
- Find related items. I use this on my TIL site to display related articles, as described in Storing and serving related documents with openai-to-sqlite and embeddings.
- Build semantic search. As shown above, an embeddings-based search engine can find content relevant to the user’s search term even if none of the keywords match.
- Implement retrieval augmented generation—the trick where you take a user’s question, find relevant documentation in your own corpus and use that to get an LLM to spit out an answer. More on that here.
- Clustering: you can find clusters of nearby items and identify patterns in a corpus of documents.
- Classification: calculate the embedding of a piece of text and compare it to pre-calculated “average” embeddings for different categories.
LLM’s new embedding features
My goal with LLM is to provide a plugin-driven abstraction around a growing collection of language models. I want to make installing, using and comparing these models as easy as possible.
The new release adds several command-line tools for working with embeddings, plus a new Python API for working with embeddings in your own code.
It also adds support for installing additional embedding models via plugins. I’ve released one plugin for this so far: llm-sentence-transformers, which adds support for new models based on the sentence-transformers library.
The example above shows how to use sentence-transformers. LLM also supports API-driven access to the OpenAI ada-002 model.
Here’s how to embed some text using ada-002, assuming you have installed LLM already:
# Set your OpenAI API key
llm keys set openai
# <paste key here>
# Embed some text
llm embed -m ada-002 -c "Hello world"This will output a huge JSON list of floating point numbers to your terminal. You can add -f base64 (or -f hex) to get that back in a different format, though none of these outputs are instantly useful.
Embeddings are much more interesting when you store them.
LLM already uses SQLite to store prompts and responses. It was a natural fit to use SQLite to store embeddings as well.
Embedding collections
LLM 0.9 introduces the concept of a collection of embeddings. A collection has a name—like readmes—and contains a set of embeddings, each of which has an ID and an embedding vector.
All of the embeddings in a collection are generated by the same model, to ensure they can be compared with each others.
The llm embed command can store the vector in the database instead of returning it to the console. Pass it the name of an existing (or to-be-created) collection and the ID to use to store the embedding.
Here we’ll store the embedding for the phrase “Hello world” in a collection called phrases with the ID hello, using that ada-002 embedding model:
llm embed phrases hello -m ada-002 -c "Hello world"Future phrases can be added without needing to specify the model again, since it is remembered by the collection:
llm embed phrases goodbye -c "Goodbye world"The llm embed-db collections shows a list of collections:
phrases: ada-002
2 embeddings
readmes: sentence-transformers/all-MiniLM-L6-v2
16796 embeddingsThe data is stored in a SQLite embeddings table with the following schema:
CREATE TABLE [collections] (
[id] INTEGER PRIMARY KEY,
[name] TEXT,
[model] TEXT
);
CREATE TABLE "embeddings" (
[collection_id] INTEGER REFERENCES [collections]([id]),
[id] TEXT,
[embedding] BLOB,
[content] TEXT,
[content_hash] BLOB,
[metadata] TEXT,
[updated] INTEGER,
PRIMARY KEY ([collection_id], [id])
);
CREATE UNIQUE INDEX [idx_collections_name]
ON [collections] ([name]);
CREATE INDEX [idx_embeddings_content_hash]
ON [embeddings] ([content_hash]);By default this is the SQLite database at the location revealed by llm embed-db path, but you can pass --database my-embeddings.db to various LLM commands to use a different database.
Each embedding vector is stored as a binary BLOB in the embedding column, consisting of those floating point numbers packed together as 32 bit floats.
The content_hash column contains a MD5 hash of the content. This helps avoid re-calculating the embedding (which can cost actual money for API-based embedding models like ada-002) unless the content has changed.
The content column is usually null, but can contain a copy of the original text content if you pass the --store option to the llm embed command.
metadata can contain a JSON object with metadata, if you pass --metadata '{"json": "goes here"}.
You don’t have to pass content using -c—you can instead pass a file path using the -i/--input option:
llm embed docs llm-setup -m ada-002 -i llm/docs/setup.mdOr pipe things to standard input like this:
cat llm/docs/setup.md | llm embed docs llm-setup -m ada-002 -i -Embedding similarity search
Once you’ve built a collection, you can search for similar embeddings using the llm similar command.
The -c "term" option will embed the text you pass in using the embedding model for the collection and use that as the comparison vector:
llm similar readmes -c sqliteYou can also pass the ID of an object in that collection to use that embedding instead. This gets you related documents, for example:
llm similar readmes sqlite-utils/README.mdThe output from this command is currently newline-delimited JSON.
Embedding in bulk
The llm embed command embeds a single string at a time. llm embed-multi is much more powerful: you can feed a CSV or JSON file, a SQLite database or even have it read from a directory of files in order to embed multiple items at once.
Many embeddings models are optimized for batch operations, so embedding multiple items at a time can provide a significant speed boost.
The embed-multi command is described in detail in the documentation. Here are a couple of fun things you can do with it.
First, I’m going to create embeddings for every single one of my Apple Notes.
My apple-notes-to-sqlite tool can export Apple Notes to a SQLite database. I’ll run that first:
apple-notes-to-sqlite notes.dbThis took quite a while to run on my machine and generated a 828M SQLite database containing 6,462 records!
Next, I’m going to embed the content of all of those notes using the sentence-transformers/all-MiniLM-L6-v2 model:
llm embed-multi notes \
-d notes.db \
--sql 'select id, title, body from notes' \
-m sentence-transformers/all-MiniLM-L6-v2This took around 15 minutes to run, and increased the size of my database by 13MB.
The --sql option here specifies a SQL query. The first column must be an id, then any subsequent columns will be concatenated together to form the content to embed.
In this case the embeddings are written back to the same notes.db database that the content came from.
And now I can run embedding similarity operations against all of my Apple notes!
llm similar notes -d notes.db -c 'ideas for blog posts'Embedding files in a directory
Let’s revisit the example from the top of this post. In this case, I’m using the --files option to search for files on disk and embed each of them:
llm embed-multi readmes \
--model sentence-transformers/all-MiniLM-L6-v2 \
--files ~/ '**/README.md'The --files option takes two arguments: a path to a directory and a pattern to match against filenames. In this case I’m searching my home directory recursively for any files named README.md.
Running this command gives me embeddings for all of my README.md files, which I can then search against like this:
llm similar readmes -c sqliteEmbeddings in Python
So far I’ve only covered the command-line tools. LLM 0.9 also introduces a new Python API for working with embeddings.
There are two aspects to this. If you just want to embed content and handle the resulting vectors yourself, you can use llm.get_embedding_model():
import llm # This takes model IDs and aliases defined by plugins: model = llm.get_embedding_model("sentence-transformers/all-MiniLM-L6-v2") vector = model.embed("This is text to embed")
vector will then be a Python list of floating point numbers.
You can serialize that to the same binary format that LLM uses like this:
binary_vector = llm.encode(vector) # And to deserialize: vector = llm.decode(binary_vector)
The second aspect of the Python API is the llm.Collection class, for working with collections of embeddings. This example code is quoted from the documentation:
import sqlite_utils import llm # This collection will use an in-memory database that will be # discarded when the Python process exits collection = llm.Collection("entries", model_id="ada-002") # Or you can persist the database to disk like this: db = sqlite_utils.Database("my-embeddings.db") collection = llm.Collection("entries", db, model_id="ada-002") # You can pass a model directly using model= instead of model_id= embedding_model = llm.get_embedding_model("ada-002") collection = llm.Collection("entries", db, model=embedding_model) # Store a string in the collection with an ID: collection.embed("hound", "my happy hound") # Or to store content and extra metadata: collection.embed( "hound", "my happy hound", metadata={"name": "Hound"}, store=True ) # Or embed things in bulk: collection.embed_multi( [ ("hound", "my happy hound"), ("cat", "my dissatisfied cat"), ], # Add this to store the strings in the content column: store=True, )
As with everything else in LLM, the goal is that anything you can do with the CLI can be done with the Python API, and vice-versa.
Clustering with llm-cluster
Another interesting application of embeddings is that you can use them to cluster content—identifying patterns in a corpus of documents.
I’ve started exploring this area with a new plugin, called llm-cluster.
You can install it like this:
llm install llm-clusterLet’s create a new collection using data pulled from GitHub. I’m going to import all of the LLM issues from the GitHub API, using my paginate-json tool:
paginate-json 'https://api.github.com/repos/simonw/llm/issues?state=all&filter=all' \
| jq '[.[] | {id: .id, title: .title}]' \
| llm embed-multi llm-issues - \
--database issues.db \
--model sentence-transformers/all-MiniLM-L6-v2 \
--storeRunning this gives me a issues.db SQLite database with 218 embeddings contained in a collection called llm-issues.
Now let’s try out the llm-cluster command, requesting ten clusters from that collection:
llm cluster llm-issues --database issues.db 10The output from this command, truncated, looks like this:
[
{
"id": "0",
"items": [
{
"id": "1784149135",
"content": "Tests fail with pydantic 2"
},
{
"id": "1837084995",
"content": "Allow for use of Pydantic v1 as well as v2."
},
{
"id": "1857942721",
"content": "Get tests passing against Pydantic 1"
}
]
},
{
"id": "1",
"items": [
{
"id": "1724577618",
"content": "Better ways of storing and accessing API keys"
},
{
"id": "1772024726",
"content": "Support for `-o key value` options such as `temperature`"
},
{
"id": "1784111239",
"content": "`--key` should be used in place of the environment variable"
}
]
},
{
"id": "8",
"items": [
{
"id": "1835739724",
"content": "Bump the python-packages group with 1 update"
},
{
"id": "1848143453",
"content": "Python library support for adding aliases"
},
{
"id": "1857268563",
"content": "Bump the python-packages group with 1 update"
}
]
}
]These look pretty good! But wouldn’t it be neat if we had a snappy title for each one?
The --summary option can provide exactly that, by piping the members of each cluster through a call to another LLM in order to generate a useful summary.
llm cluster llm-issues --database issues.db 10 --summaryThis uses gpt-3.5-turbo to generate a summary for each cluster, with this default prompt:
Short, concise title for this cluster of related documents.
The results I got back are pretty good, including:
- Template Storage and Management Improvements
- Package and Dependency Updates and Improvements
- Adding Conversation Mechanism and Tools
I tried the same thing using a Llama 2 model running on my own laptop, with a custom prompt:
llm cluster llm-issues --database issues.db 10 \
--summary --model mlc-chat-Llama-2-13b-chat-hf-q4f16_1 \
--prompt 'Concise title for this cluster of related documents, just return the title'
I didn’t quite get what I wanted! Llama 2 is proving a lot harder to prompt, so each cluster came back with something that looked like this:
Sure! Here’s a concise title for this cluster of related documents:
“Design Improvements for the Neat Prompt System”
This title captures the main theme of the documents, which is to improve the design of the Neat prompt system. It also highlights the focus on improving the system’s functionality and usability
llm-cluster only took a few hours to throw together, which I’m seeing as a positive indicator that the LLM library is developing in the right direction.
Future plans
The two future features I’m most excited about are indexing and chunking.
Indexing
The llm similar command and collection.similar() Python method currently use effectively the slowest brute force approach possible: calculate a cosine difference between input vector and every other embedding in the collection, then sort the results.
This works fine for collections with a few hundred items, but will start to suffer for collections of 100,000 or more.
There are plenty of potential ways of speeding this up: you can run a vector index like FAISS or hnswlib, use a database extension like sqlite-vss or pgvector, or turn to a hosted vector database like Pinecone or Milvus.
With this many potential solutions, the obvious answer for LLM is to address this with plugins.
I’m still thinking through the details, but the core idea is that users should be able to define an index against one or more collections, and LLM will then coordinate updates to that index. These may not happen in real-time—some indexes can be expensive to rebuild, so there are benefits to applying updates in batches.
I experimented with FAISS earlier this year in datasette-faiss. That’s likely to be the base for my first implementation.
The embeddings table has an updated timestamp column to support this use-case—so indexers can run against just the items that have changed since the last indexing run.
Follow issue #216 for updates on this feature.
Chunking
When building an embeddings-based search engine, the hardest challenge is deciding how best to “chunk” the documents.
Users will type in short phrases or questions. The embedding for a four word question might not necessarily map closely to the embedding of a thousand word article, even if the article itself should be a good match for that query.
To maximize the chance of returning the most relevant content, we need to be smarter about what we embed.
I’m still trying to get a good feeling for the strategies that make sense here. Some that I’ve seen include:
- Split a document up into fixed length shorter segments.
- Split into segments but including a ~10% overlap with the previous and next segments, to reduce problems caused by words and sentences being split in a way that disrupts their semantic meaning.
- Splitting by sentence, using NLP techniques.
- Splitting into higher level sections, based on things like document headings.
Then there are more exciting, LLM-driven approaches:
- Generate an LLM summary of a document and embed that.
- Ask an LLM “What questions are answered by the following text?” and then embed each of the resulting questions!
It’s possible to try out these different techniques using LLM already: write code that does the splitting, then feed the results to Collection.embed_multi() or llm embed-multi.
But... it would be really cool if LLM could split documents for you—with the splitting techniques themselves defined by plugins, to make it easy to try out new approaches.
Get involved
It should be clear by now that the potential scope of the LLM project is enormous. I’m trying to use plugins to tie together an enormous and rapidly growing ecosystem of models and techniques into something that’s as easy for people to work with and build on as possible.
There are plenty of ways you can help!
- Join the #llm Discord to talk about the project.
- Try out plugins and run different models with them. There are 12 plugins already, and several of those can be used to run dozens if not hundreds of models (llm-mlc, llm-gpt4all and llm-llama-cpp in particular). I’ve hardly scratched the surface of these myself, and I’m testing exclusively on Apple Silicon. I’m really keen to learn more about which models work well, which models don’t and which perform the best on different hardware.
- Try building a plugin for a new model. My dream here is that every significant Large Language Model will have an LLM plugin that makes it easy to install and use.
- Build stuff using LLM and let me know what you’ve built. Nothing fuels an open source project more than stories of cool things people have built with it.
Datasette 1.0a4 and 1.0a5, plus weeknotes 21 days ago
Two new alpha releases of Datasette, plus a keynote at WordCamp, a new LLM release, two new LLM plugins and a flurry of TILs.
Datasette 1.0a5
Released this morning, Datasette 1.0a5 has some exciting new changes driven by Datasette Cloud and the ongoing march towards Datasette 1.0.
Alex Garcia is working with me on Datasette Cloud and Datasette generally, generously sponsored by Fly.
Two of the changes in 1.0a5 were driven by Alex:
New
datasette.yaml(or.json) configuration file, which can be specified usingdatasette -c path-to-file. The goal here to consolidate settings, plugin configuration, permissions, canned queries, and other Datasette configuration into a single single file, separate frommetadata.yaml. The legacysettings.jsonconfig file used for Configuration directory mode has been removed, anddatasette.yamlhas a"settings"section where the same settings key/value pairs can be included. In the next future alpha release, more configuration such as plugins/permissions/canned queries will be moved to thedatasette.yamlfile. See #2093 for more details.
Right from the very start of the project, Datasette has supported specifying metadata about databases—sources, licenses, etc, as a metadata.json file that can be passed to Datasette like this:
datasette data.db -m metadata.jsonOver time, the purpose and uses of that file has expanded in all kinds of different directions. It can be used for plugin settings, and to set preferences for a table default page size, default facets etc), and even to configure access permissions for who can view what.
The name metadata.json is entirely inappropriate for what the file actually does. It’s a mess.
I’ve always had a desire to fix this before Datasette 1.0, but it never quite got high up enough the priority list for me to spend time on it.
Alex expressed interest in fixing it, and has started to put a plan into motion for cleaning it up.
More details in the issue.
The Datasette
_internaldatabase has had some changes. It no longer shows up in thedatasette.databaseslist by default, and is now instead available to plugins using thedatasette.get_internal_database(). Plugins are invited to use this as a private database to store configuration and settings and secrets that should not be made visible through the default Datasette interface. Users can pass the new--internal internal.dboption to persist that internal database to disk. (#2157).
This was the other initiative driven by Alex. In working on Datasette Cloud we realized that it’s actually quite common for plugins to need somewhere to store data that shouldn’t necessarily be visible to regular users of a Datasette instance—things like tokens created by datasette-auth-tokens, or the progress bar mechanism used by datasette-upload-csvs.
Alex pointed out that the existing _internal database for Datasette could be expanded to cover these use-cases as well. #2157 has more details on how we agreed this should work.
The other changes in 1.0a5 were driven by me:
When restrictions are applied to API tokens, those restrictions now behave slightly differently: applying the
view-tablerestriction will imply the ability toview-databasefor the database containing that table, and bothview-tableandview-databasewill implyview-instance. Previously you needed to create a token with restrictions that explicitly listedview-instanceandview-databaseandview-tablein order to view a table without getting a permission denied error. (#2102)
I described finely-grained permissions for access tokens in my annotated release notes for 1.0a2.
They provide a mechanism for creating an API token that’s only allowed to perform a subset of actions on behalf of the user.
In trying these out for Datasette Cloud I came across a nasty usability flaw. You could create a token that was restricted to view-table access for a specific table... and it wouldn’t work. Because the access code for that view would check for view-instance and view-database permission first.
1.0a5 fixes that, by adding logic that says that if a token can view-table that implies it can view-database for the database containing that table, and view-instance for the overall instance.
This change took quite some time to develop, because any time I write code involving permissions I like to also include extremely comprehensive automated tests.
The
-s/--settingoption can now take dotted paths to nested settings. These will then be used to set or over-ride the same options as are present in the new configuration file. (#2156)
This is a fun little detail inspired by Alex’s configuration work.
I run a lot of different Datasette instances, often on an ad-hoc basis.
I sometimes find it frustrating that to use certain features I need to create a metadata.json (soon to be datasette.yml) configuration file, just to get something to work.
Wouldn’t it be neat if every possible setting for Datasette could be provided both in a configuration file or as command-line options?
That’s what the new --setting option aims to solve. Anything that can be represented as a JSON or YAML configuration can now also be represented as key/value pairs on the command-line.
Here’s an example from my initial issue comment:
datasette \
-s settings.sql_time_limit_ms 1000 \
-s plugins.datasette-auth-tokens.manage_tokens true \
-s plugins.datasette-auth-tokens.manage_tokens_database tokens \
-s plugins.datasette-ripgrep.path "/home/simon/code-to-search" \
-s databases.mydatabase.tables.example_table.sort created \
mydatabase.db tokens.dbOnce this feature is complete, the above will behave the same as a datasette.yml file containing this:
plugins:
datasette-auth-tokens:
manage_tokens: true
manage_tokens_database: tokens
datasette-ripgrep:
path: /home/simon/code-to-search
databases:
mydatabase:
tables:
example_table:
sort: created
settings:
sql_time_limit_ms: 1000I’ve experimented with ways of turning key/value pairs into nested JSON objects before, with my json-flatten library.
This time I took a slightly different approach. In particular, if you need to pass a nested JSON object (such as an array) which isn’t easily represented using key.nested notation, you can pass it like this instead:
datasette data.db \
-s plugins.datasette-complex-plugin.configs \
'{"foo": [1,2,3], "bar": "baz"}'Which would convert to the following equivalent YAML:
plugins:
datasette-complex-plugin:
configs:
foo:
- 1
- 2
- 3
bar: bazThese examples don’t quite work yet, because the plugin configuration hasn’t migrated to datasette.yml—but it should work for the next alpha.
New
--actor '{"id": "json-goes-here"}'option for use withdatasette --getto treat the simulated request as being made by a specific actor, see datasette --get. (#2153)
This is a fun little debug helper I built while working on restricted tokens.
The datasette --get /... option is a neat trick that can be used to simulate an HTTP request through the Datasette instance, without even starting a server running on a port.
I use it for things like generating social media card images for my TILs website.
The new --actor option lets you add a simulated actor to the request, which is useful for testing out things like configured authentication and permissions.
A security fix in Datasette 1.0a4
Datasette 1.0a4 has a security fix: I realized that the API explorer I added in the 1.0 alpha series was exposing the names of databases and tables (though not their actual content) to unauthenticated users, even for Datasette instances that were protected by authentication.
I issued a GitHub security advisory for this: Datasette 1.0 alpha series leaks names of databases and tables to unauthenticated users, which has since been issued a CVE, CVE-2023-40570—GitHub is a CVE Numbering Authority which means their security team are trusted to review such advisories and issue CVEs where necessary.
I expect the impact of this vulnerability to be very small: outside of Datasette Cloud very few people are running the Datasette 1.0 alphas on the public internet, and it’s possible that the set of those users who are also authenticating their instances to provide authenticated access to private data—especially where just the database and table names of that data is considered sensitive—is an empty set.
Datasette Cloud itself has detailed access logs primarily to help evaluate this kind of threat. I’m pleased to report that those logs showed no instances of an unauthenticated user accessing the pages in question prior to the bug being fixed.
A keynote at WordCamp US
Last Friday I gave a keynote at WordCamp US on the subject of Large Language Models.
I used MacWhisper and my annotated presentation tool to turn that into a detailed transcript, complete with additional links and context: Making Large Language Models work for you.
llm-openrouter and llm-anyscale-endpoints
I released two new plugins for LLM, which lets you run large language models either locally or via APIs, as both a CLI tool and a Python library.
Both plugins provide access to API-hosted models:
- llm-openrouter provides access to models hosted by OpenRouter. Of particular interest here is Claude—I’m still on the waiting list for the official Claude API, but in the meantime I can pay for access to it via OpenRouter and it works just fine. Claude has a 100,000 token context, making it a really great option for working with larger documents.
- llm-anyscale-endpoints is a similar plugin that instead works with Anyscale Endpoints. Anyscale provide Llama 2 and Code Llama at extremely low prices—between $0.25 and $1 per million tokens, depending on the model.
These plugins were very quick to develop.
Both OpenRouter and Anyscale Endpoints provide API endpoints that emulate the official OpenAI APIs, including the way the handle streaming tokens.
LLM already has code for talking to those endpoints via the openai Python library, which can be re-pointed to another backend using the officially supported api_base parameter.
So the core code for the plugins ended up being less than 30 lines each: llm_openrouter.py and llm_anyscale_endpoints.py.
llm 0.8
I shipped LLM 0.8 a week and a half ago, with a bunch of small changes.
The most significant of these was a change to the default llm logs output, which shows the logs (recorded in SQLite) of the previous prompts and responses you have sent through the tool.
This output used to be JSON. It’s now Markdown, which is both easier to read and can be pasted into GitHub Issue comments or Gists or similar to share the results with other people.
The release notes for 0.8 describe all of the other improvements.
sqlite-utils 3.35
The 3.35 release of sqlite-utils was driven by LLM.
sqlite-utils has a mechanism for adding foreign keys to an existing table—something that’s not supported by SQLite out of the box.
That implementation used to work using a deeply gnarly hack: it would switch the sqlite_master table over to being writable (using PRAGMA writable_schema = 1), update that schema in place to reflect the new foreign keys and then toggle writable_schema = 0 back again.
It turns out there are Python installations out there—most notably the system Python on macOS—which completely disable the ability to write to that table, no matter what the status of the various pragmas.
I was getting bug reports from LLM users who were running into this. I realized that I had a solution for this mostly implemented already: the sqlite-utils transform() method, which can apply all sorts of complex schema changes by creating a brand new table, copying across the old data and then renaming it to replace the old one.
So I dropped the old writable_schema mechanism entirely in favour of .transform()—it’s slower, because it requires copying the entire table, but it doesn’t have weird edge-cases where it doesn’t work.
Since sqlite-utils supports plugins now, I realized I could set a healthy precedent by making the removed feature available in a new plugin: sqlite-utils-fast-fks, which provides the following command for adding foreign keys the fast, old way (provided your installation supports it):
sqlite-utils install sqlite-utils-fast-fks
sqlite-utils fast-fks my_database.db places country_id country idI’ve always admired how jQuery uses plugins to keep old features working on an opt-in basis after major version upgrades. I’m excited to be able to apply the same pattern for sqlite-utils.
paginate-json 1.0
paginate-json is a tiny tool I first released a few years ago to solve a very specific problem.
There’s a neat pattern in some JSON APIs where the HTTP link header is used to indicate subsequent pages of results.
The best example I know of this is the GitHub API. Run this to see what it looks like here I’m using the events API):
curl -i \
https://api.github.com/users/simonw/eventsHere’s a truncated example of the output:
HTTP/2 200
server: GitHub.com
content-type: application/json; charset=utf-8
link: <https://api.github.com/user/9599/events?page=2>; rel="next", <https://api.github.com/user/9599/events?page=9>; rel="last"
[
{
"id": "31467177730",
"type": "PushEvent",
The link header there specifies a next and last URL that can be used for pagination.
To fetch all available items, you can follow the next link repeatedly until it runs out.
My paginate-json tool can follow these links for you. If you run it like this:
paginate-json \
https://api.github.com/users/simonw/eventsIt will output a single JSON array consisting of the results from every available page.
The 1.0 release adds a bunch of small features, but also marks my confidence in the stability of the design of the tool.
The Datasette JSON API has supported link pagination for a while—you can use paginate-json with Datasette like this, taking advantage of the new --key option to paginate over the array of objects returned in the "rows" key:
paginate-json \
'https://datasette.io/content/pypi_releases.json?_labels=on' \
--key rows \
--nlThe --nl option here causes paginate-json to output the results as newline-delimited JSON, instead of bundling them together into a JSON array.
Here’s how to use sqlite-utils insert to insert that data directly into a fresh SQLite database:
paginate-json \
'https://datasette.io/content/pypi_releases.json?_labels=on' \
--key rows \
--nl | \
sqlite-utils insert data.db releases - \
--nl --flattenReleases this week
-
paginate-json 1.0—2023-08-30
Command-line tool for fetching JSON from paginated APIs -
datasette-auth-tokens 0.4a2—2023-08-29
Datasette plugin for authenticating access using API tokens -
datasette 1.0a5—2023-08-29
An open source multi-tool for exploring and publishing data -
llm-anyscale-endpoints 0.2—2023-08-25
LLM plugin for models hosted by Anyscale Endpoints -
datasette-jellyfish 2.0—2023-08-24
Datasette plugin adding SQL functions for fuzzy text matching powered by Jellyfish -
datasette-configure-fts 1.1.2—2023-08-23
Datasette plugin for enabling full-text search against selected table columns -
datasette-ripgrep 0.8.1—2023-08-21
Web interface for searching your code using ripgrep, built as a Datasette plugin -
datasette-publish-fly 1.3.1—2023-08-21
Datasette plugin for publishing data using Fly -
llm-openrouter 0.1—2023-08-21
LLM plugin for models hosted by OpenRouter -
llm 0.8—2023-08-21
Access large language models from the command-line -
sqlite-utils-fast-fks 0.1—2023-08-18
Fast foreign key addition for sqlite-utils -
datasette-edit-schema 0.5.3—2023-08-18
Datasette plugin for modifying table schemas -
sqlite-utils 3.35—2023-08-18
Python CLI utility and library for manipulating SQLite databases
TIL this week
- Streaming output of an indented JSON array—2023-08-30
- Downloading partial YouTube videos with ffmpeg—2023-08-26
- Compile and run a new SQLite version with the existing sqlite3 Python library on macOS—2023-08-22
- Configuring Django SQL Dashboard for Fly PostgreSQL—2023-08-22
- Calculating the size of a SQLite database file using SQL—2023-08-21
- Updating stable docs in ReadTheDocs without pushing a release—2023-08-21
- A shell script for running Go one-liners—2023-08-20
- A one-liner to output details of the current Python’s SQLite—2023-08-19
- A simple pattern for inlining binary content in a Python script—2023-08-19
- Running multiple servers in a single Bash script—2023-08-17
Making Large Language Models work for you 24 days ago
I gave an invited keynote at WordCamp 2023 in National Harbor, Maryland on Friday.
I was invited to provide a practical take on Large Language Models: what they are, how they work, what you can do with them and what kind of things you can build with them that could not be built before.
As a long-time fan of WordPress and the WordPress community, which I think represents the very best of open source values, I was delighted to participate.
You can watch my talk on YouTube here. Here are the slides and an annotated transcript, prepared using the custom tool I described in this post.
- What they are
- How they work
- How to use them
- Personal AI ethics
- What we can build with them
- Giving them access to tools
- Retrieval augmented generation
- Embeddings and semantic search
- ChatGPT Code Interpreter
- How they’re trained
- Openly licensed models
- Prompt injection
- Helping everyone program computers
Datasette Cloud, Datasette 1.0a3, llm-mlc and more one month ago
Datasette Cloud is now a significant step closer to general availability. The Datasette 1.03 alpha release is out, with a mostly finalized JSON format for 1.0. Plus new plugins for LLM and sqlite-utils and a flurry of things I’ve learned.
Datasette Cloud
Yesterday morning we unveiled the new Datasette Cloud blog, and kicked things off there with two posts:
- Welcome to Datasette Cloud provides an introduction to the product: what it can do so far, what’s coming next and how to sign up to try it out.
- Introducing datasette-write-ui: a Datasette plugin for editing, inserting, and deleting rows introduces a brand new plugin, datasette-write-ui—which finally adds a user interface for editing, inserting and deleting rows to Datasette.
Here’s a screenshot of the interface for creating a new private space in Datasette Cloud:
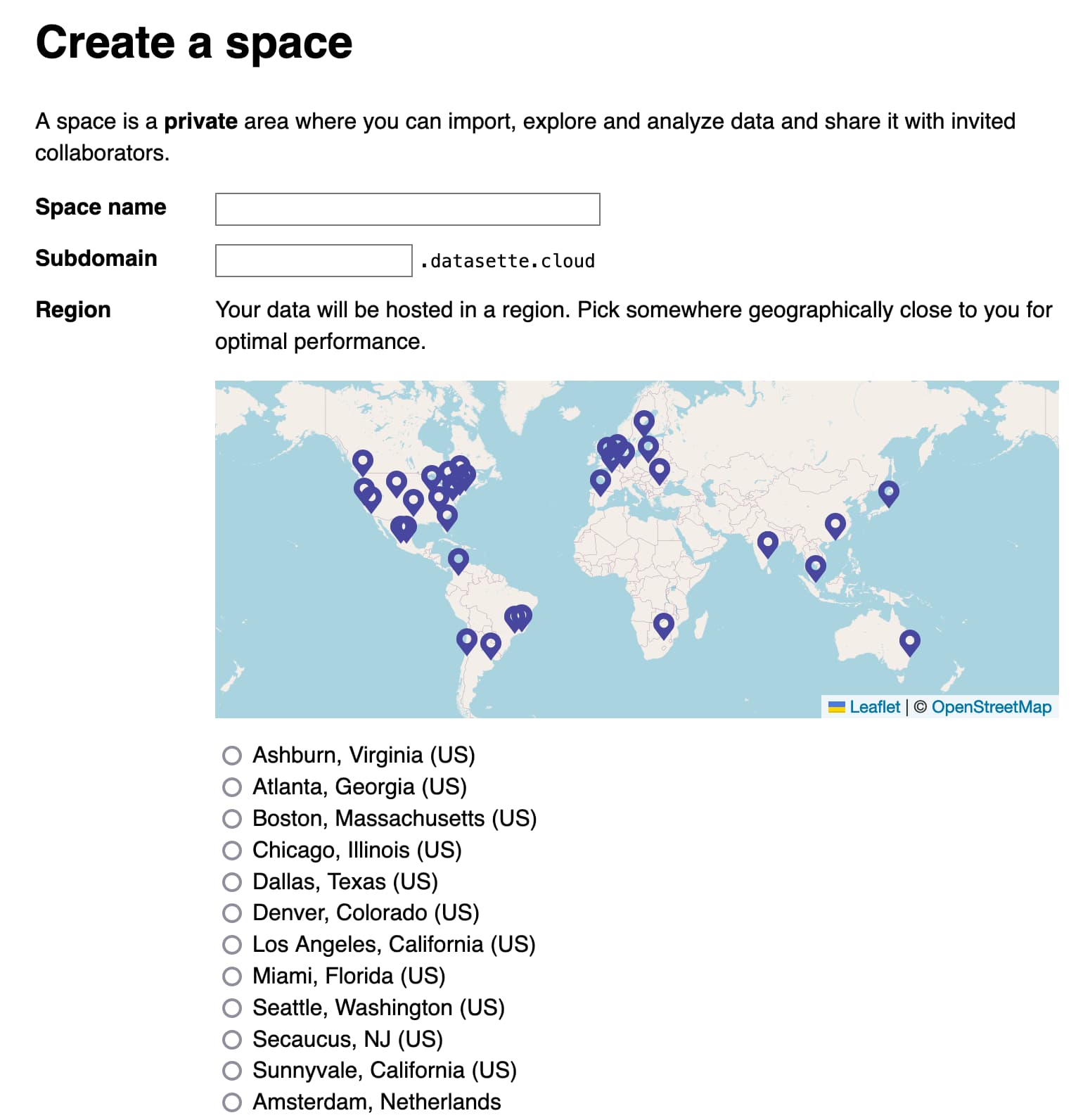
datasette-write-ui is particularly notable because it was written by Alex Garcia, who is now working with me to help get Datasette Cloud ready for general availability.
Alex’s work on the project is being supported by Fly.io, in a particularly exciting form of open source sponsorship. Datasette Cloud is already being built on Fly, but as part of Alex’s work we’ll be extensively documenting what we learn along the way about using Fly to build a multi-tenant SaaS platform.
Alex has some very cool work with Fly’s Litestream in the pipeline which we hope to talk more about shortly.
Since this is my first time building a blog from scratch in quite a while, I also put together a new TIL on Building a blog in Django.
The Datasette Cloud work has been driving a lot of improvements to other parts of the Datasette ecosystem, including improvements to datasette-upload-dbs and the other big news this week: Datasette 1.0a3.
Datasette 1.0a3
Datasette 1.0 is the first version of Datasette that will be marked as “stable”: if you build software on top of Datasette I want to guarantee as much as possible that it won’t break until Datasette 2.0, which I hope to avoid ever needing to release.
The three big aspects of this are:
- A stable plugins interface, so custom plugins continue to work
- A stable JSON API format, for integrations built against Datasette
- Stable template contexts, so that custom templates won’t be broken by minor changes
The 1.0 alpha 3 release primarily focuses on the JSON support. There’s a new, much more intuitive default shape for both the table and the arbitrary query pages, which looks like this:
{
"ok": true,
"rows": [
{
"id": 3,
"name": "Detroit"
},
{
"id": 2,
"name": "Los Angeles"
},
{
"id": 4,
"name": "Memnonia"
},
{
"id": 1,
"name": "San Francisco"
}
],
"truncated": false
}This is a huge improvement on the old format, which featured a vibrant mess of top-level keys and served the rows up as an array-of-arrays, leaving the user to figure out which column was which by matching against "columns".
The new format is documented here. I wanted to get this in place as soon as possible for Datasette Cloud (which is running this alpha), since I don’t want to risk paying customers building integrations that would later break due to 1.0 API changes.
llm-mlc
My LLM tool provides a CLI utility and Python library for running prompts through Large Language Models. I added plugin support to it a few weeks ago, so now it can support additional models through plugins—including a variety of models that can run directly on your own device.
For a while now I’ve been trying to work out the easiest recipe to get a Llama 2 model running on my M2 Mac with GPU acceleration.
I finally figured that out the other week, using the excellent MLC Python library.
I built a new plugin for LLM called llm-mlc. I think this may now be one of the easiest ways to run Llama 2 on an Apple Silicon Mac with GPU acceleration.
Here are the steps to try it out. First, install LLM—which is easiest with Homebrew:
brew install llmIf you have a Python 3 environment you can run pip install llm or pipx install llm instead.
Next, install the new plugin:
llm install llm-mlcThere’s an additional installation step which I’ve not yet been able to automate fully—on an M1/M2 Mac run the following:
llm mlc pip install --pre --force-reinstall \
mlc-ai-nightly \
mlc-chat-nightly \
-f https://mlc.ai/wheelsInstructions for other platforms can be found here.
Now run this command to finish the setup (which configures git-lfs ready to download the models):
llm mlc setupAnd finally, you can download the Llama 2 model using this command:
llm mlc download-model Llama-2-7b-chat --alias llama2And run a prompt like this:
llm -m llama2 'five names for a cute pet ferret'It’s still more steps than I’d like, but it seems to be working for people!
As always, my goal for LLM is to grow a community of enthusiasts who write plugins like this to help support new models as they are released. That’s why I put a lot of effort into building this tutorial about Writing a plugin to support a new model.
Also out now: llm 0.7, which mainly adds a new mechanism for adding custom aliases to existing models:
llm aliases set turbo gpt-3.5-turbo-16k
llm -m turbo 'An epic Greek-style saga about a cheesecake that builds a SQL database from scratch'openai-to-sqlite and embeddings for related content
A smaller release this week: openai-to-sqlite 0.4, an update to my CLI tool for loading data from various OpenAI APIs into a SQLite database.
My inspiration for this release was a desire to add better related content to my TIL website.
Short version: I did exactly that! Each post on that site now includes a list of related posts that are generated using OpenAI embeddings, which help me plot posts that are semantically similar to each other.
I wrote up a full TIL about how that all works: Storing and serving related documents with openai-to-sqlite and embeddings—scroll to the bottom of that post to see the new related content in action.
I’m fascinated by embeddings. They’re not difficult to run using locally hosted models either—I hope to add a feature to LLM to help with that soon.
Getting creative with embeddings by Amelia Wattenberger is a great example of some of the more interesting applications they can be put to.
sqlite-utils-jq
A tiny new plugin for sqlite-utils, inspired by this Hacker News comment and written mainly as an excuse for me to exercise that new plugins framework a little more.
sqlite-utils-jq adds a new jq() function which can be used to execute jq programs as part of a SQL query.
Install it like this:
sqlite-utils install sqlite-utils-jqNow you can do things like this:
sqlite-utils memory "select jq(:doc, :expr) as result" \
-p doc '{"foo": "bar"}' \
-p expr '.foo'You can also use it in combination with sqlite-utils-litecli to run that new function as part of an interactive shell:
sqlite-utils install sqlite-utils-litecli
sqlite-utils litecli data.db
# ...
Version: 1.9.0
Mail: https://groups.google.com/forum/#!forum/litecli-users
GitHub: https://github.com/dbcli/litecli
data.db> select jq('{"foo": "bar"}', '.foo')
+------------------------------+
| jq('{"foo": "bar"}', '.foo') |
+------------------------------+
| "bar" |
+------------------------------+
1 row in set
Time: 0.031s
Other entries this week
How I make annotated presentations describes the process I now use to create annotated presentations like this one for Catching up on the weird world of LLMs (now up to over 17,000 views on YouTube!) using a new custom annotation tool I put together with the help of GPT-4.
A couple of highlights from my TILs:
- Catching up with the Cosmopolitan ecosystem describes my latest explorations of Cosmopolitan and Actually Portable Executable, based on an update I heard from Justine Tunney.
- Running a Django and PostgreSQL development environment in GitHub Codespaces shares what I’ve learned about successfully running a Django and PostgreSQL development environment entirely through the browser using Codespaces.
Releases this week
-
openai-to-sqlite 0.4—2023-08-15
Save OpenAI API results to a SQLite database -
llm-mlc 0.5—2023-08-15
LLM plugin for running models using MLC -
datasette-render-markdown 2.2.1—2023-08-15
Datasette plugin for rendering Markdown -
db-build 0.1—2023-08-15
Tools for building SQLite databases from files and directories -
paginate-json 0.3.1—2023-08-12
Command-line tool for fetching JSON from paginated APIs -
llm 0.7—2023-08-12
Access large language models from the command-line -
sqlite-utils-jq 0.1—2023-08-11
Plugin adding a jq() SQL function to sqlite-utils -
datasette-upload-dbs 0.3—2023-08-10
Upload SQLite database files to Datasette -
datasette 1.0a3—2023-08-09
An open source multi-tool for exploring and publishing data
TIL this week
- Processing a stream of chunks of JSON with ijson—2023-08-16
- Building a blog in Django—2023-08-15
- Storing and serving related documents with openai-to-sqlite and embeddings—2023-08-15
- Combined release notes from GitHub with jq and paginate-json—2023-08-12
- Catching up with the Cosmopolitan ecosystem—2023-08-10
- Running a Django and PostgreSQL development environment in GitHub Codespaces—2023-08-10
- Scroll to text fragments—2023-08-08