21/02/2023-27/02/2023
Microblogging links in weeklyOSM [1] | © Pieter Vander Vennet | map data © OpenStreetMap contributors
Breaking news
- OSMTech announced, on March 2, that the long-planned import of the content from the old forum into the new OSM Community forum will take place in the coming week. There may be some associated downtime of the Community site.
About us
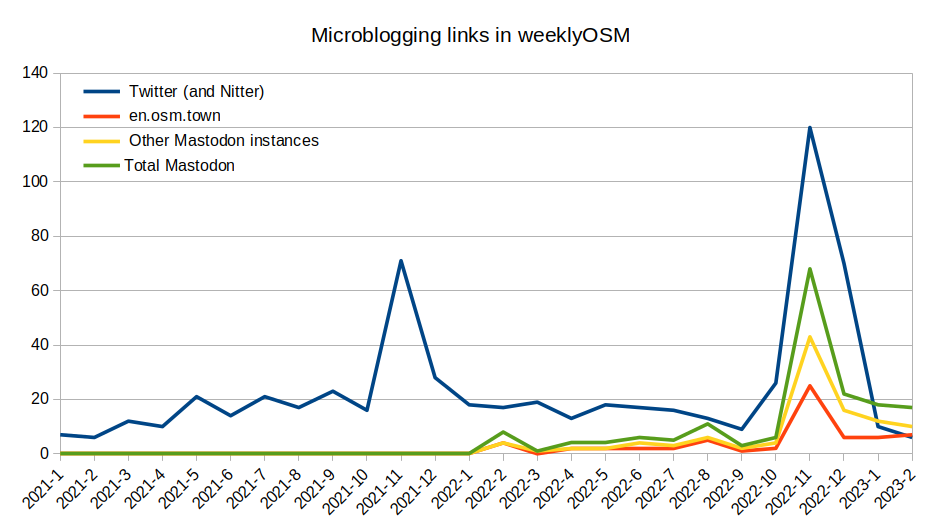
- [1] Pieter Vander Vennet was interested to know how much of a transition has been made from Twitter to Mastodon by the OpenStreetMap community. His approach was to count links from weeklyOSM to the two sites, allowing a comparison over quite a long time, back to 2020. It appears that Mastodon has become more used over the past two months. November was an anomaly because of both the #30dayMapChallenge and the listing of OSM-relevant Mastodon accounts.
Mapping
- Martijn van Exel has written two blog articles on how to capture and upload 360° imagery with Mapillary. The first covers capturing images while walking and the second biking.
- Pete Masters passed on the thank you from Dr Bilgehan Çevik, an orthopaedic surgeon working in Ankara, Turkey, for the help they received through Organic Maps from OSM.
- Alex Seidel (Supaplex030) explained how streetside parking tags have been overhauled, mainly to make them easier to understand. He provides overpass turbo queries to detect older usage, a tool to assist in updating the tagging, and tips for use in JOSM, including a parking-specific style.
- Requests have been made for comments on the
following proposals:
highway=trailheadfor mapping a designated or customary place where a trip on a trail begins or ends.- Public transport auditory information, a tagging scheme for describing what kind of auditory information is available on public transport stations and platforms.
- Voting on
emergency=fire_service_inlet, for mapping an inlet to a building’s firefighting system, has finished and the proposal was successful with 26 votes for, 1 vote against and 0 abstentions.
Community
- Grant Slater, from OSM Ops, asked users of the old forum to check their own posts in a test import of the forum to Discourse. The import is a snapshot from 2 February 2023.
- Alan McConchie has extended the entry deadline for the ‘OSM Oscars‘ until Tuesday 7 March. So if you still want to submit nominations, please hurry.
- Pete Masters and Rubén Martín have published HOT Community Weeknotes: 8 / 2023, discussing recent activities and what’s coming up for the humanitarian open mapping community.
- Said Turksever and the Turkish OSM community have been chosen as Mappers of the Month by UN Mappers for the invaluable coordination of the mapping work done in the aftermath of the earthquake that hit Syria and Turkey on 6 February.
- OpenStreetMap US provided an update on progress with the Trails Stewardship Initiative. Using selected areas in the Pacific Northwest, familiar to a range of stakeholders, tagging and mapping approaches have been trialled with both land managers and app developers.
OpenStreetMap Foundation
- The OSMF is looking for volunteers with skills in graphic design to help add visual storytelling to their blog, social media, and other channels in order to support OSM events, fundraising, developer projects, and more.
Local chapter news
- Congratulations to Diane Fritz, Matthew Whilden, and Priyanka Miller, who have been elected to the OpenStreetMap US Board.
Events
- Unique Mappers Network Nigeria are holding ‘Let’s DigitAll for Women’ starting on Wednesday 8 March, International Womens’ Day (IWD2023). The event incorporates a panel session (8 March), three training sessions (8 to 10 March), and a two week long mapathon and school outreach finishing on 22 March.
- A Trufi Association webinar, to be held on Tuesday 7 March, ‘Mobility as a Service (MaaS) in the Global South and Sustainable Mobility’ will include a discussion of how OSM democratises mobility data.
OSM research
- Moritz Schott, Sven Lautenbach, Leonie Großchen, and Alexander Zipf presented a new tool in their paper ‘OpenStreetMap Element Vectorisation: A Tool for High Resolution Data Insights and its Usability in the Land-use and Land-cover Domain’. The OpenStreetMap Element Vectorisation addresses the much-discussed issue of fitness for purpose. It currently provides access to 32 attributes at the level of single OSM objects.
Maps
- TrekkingTrails reviewed

an extensive range of eleven OSM-based maps designed for hikers. - Where would your balloon fly if you could launch it from a place of your choice? Using OSM and meteorological data from the past 91 days this map will display its trip around the world.
- Tracestrack has open sourced their bus route Carto-CSS map style. This style focuses on bus/tram routes and stops. With colour-coded routes, the style tries to explore a better way to present many bus routes.
Software
- Researchers from ETH Zurich presented Eduard, machine learning-based software for generating shaded relief maps, inspired by the work of Swiss cartographer Eduard Imhof.
Programming
- OrganicMaps are a participant in the 2023 Google Summer of Code, and have listed ideas for projects on GitHub.
- Martijn van Exel wrote a longish post about how he used osm2pgsql to set up and maintain the database that powers Resto-Bot, the bot that toots out the OSM database every day for restaurant features that have not been updated in more than five years.
- Jochen Topf described how he has extended the tile-expiry feature of osm2pgsql. Tiles containing changed data have always been written to a list in a file, allowing selective rendering of the affected tiles. In order to work with generalised features the approach needed to be enhanced: firstly, by storing the list in a database table, and secondly, by keeping multiple lists allowing features or layers to be expired independently.
Did you know …
- … there is a MapRoulette plugin for JOSM?
- … the Gefahrenstellen.de (danger point) project? Arno Wolter, one of the three founders and CEO of the Initiative for Safer Roads, talked about their new project Gefahrenstellen.de, which seeks to help parents and schoolchildren select the path to school with the least traffic and risk. The project uses HeiGIT’s openrouteservice as a routing service, which in turn uses OSM data.
- … the TreeTalk map can help you answer the question ‘What kind of tree is that?’ The map provides tree information for 26 boroughs in London.
Other “geo” things
- The rivers of Europe! Coloured according to their basins and scaled by the volumes of water flowing through them; data from hydrosheds.org.
- Christopher Beddow discussed the challenge of maps covering fractal levels of detail, and attempting to symmetrically represent the world, or at least how we perceive it.
- The Trufi Association’s volunteer of the month is Eva Asturizaga. If you would like to volunteer for the Trufi Association you can find out how on their website.
Upcoming Events
| Where | What | Online | When | Country |
|---|---|---|---|---|
| Budapest | Hiking by the pipeline between Barosstelep and Albertfalva
|
2023-03-04 |  |
|
| 泉大津市 |
マッピングパーティーin泉大津
|
2023-03-04 |  |
|
| Nantes | Découverte du projet cartographique OpenStreetMap |
2023-03-04 |  |
|
| 荒尾市 |
地域の「今」を記録して残そう!
みんなで作る!
みんなが使える無料のマップ
~変わりゆく荒尾~
|
2023-03-05 | |
|
| Leinfelden-Echterdingen | OpenStreetMap auf der didacta 2023 in Stuttgart |
2023-03-07 – 2023-03-11 |  |
|
| MapRoulette Monthly Community Meeting |
2023-03-07 | |||
| OSMF Engineering Working Group meeting |
2023-03-07 | |||
| Missing Maps London Mapathon |
2023-03-07 | |||
| Berlin | OSM-Verkehrswende #45 (Online) |
✓ | 2023-03-07 | |
| HOT Tasking Manager Monthly Meet Up |
2023-03-08 | |||
| HOT Tasking Manager Monthly Meet Up |
2023-03-08 | |||
| Aachen | 2. Treffen Aachener Stammtisch |
2023-03-08 | |
|
| Stainach-Pürgg | 8. Virtueller OpenStreetMap Stammtisch Österreich |
2023-03-08 |  |
|
| Salt Lake City | OSM Utah Monthly Map Night |
2023-03-09 |  |
|
| Chippewa Township | Michigan OpenStreetMap Meetup |
2023-03-09 | |
|
| Fort Collins | Special Presentation: Eric Theise, Carto-OSC |
2023-03-09 | |
|
| Hlavní město Praha | Missing Maps Mapathon na ČVUT |
2023-03-09 |  |
|
| Paris | Rencontre contributeurs à Paris |
2023-03-09 | |
|
| Berlin | 177. Berlin-Brandenburg OpenStreetMap Stammtisch (Online)
|
✓ | 2023-03-09 | |
| München | Münchner OSM-Treffen |
2023-03-09 | |
|
| Winterthur | OSM-Stammtisch @Init7 |
2023-03-10 |  |
|
| Fort Collins | A Synesthete’s Atlas – Eric Theise & cellist Daniel
Zamzow |
2023-03-11 | |
|
| Kalyani Nagar | Pune Mapping Party |
2023-03-11 |  |
|
| København | OSMmapperCPH |
2023-03-12 |  |
|
| Pueblo | A Synesthete’s Atlas – Eric Theise & Bob
Marsh’s Spontaneous Combustion Arts Performance Ensemble
|
2023-03-13 | |
|
| 臺北市 | OpenStreetMap x Wikidata 月聚會 #50 |
2023-03-13 |  |
|
| HOT Open Tech and Innovation WG |
2023-03-14 | |||
| HOT Open Tech and Innovation WG |
2023-03-14 | |||
| San Jose | South Bay Map Night |
✓ | 2023-03-15 | |
| Aachen | 2023-03-17 | |
||
| Berlin | Missing Maps Mapathon in Berlin |
2023-03-18 | |
|
| Toulouse | Réunion du groupe local de Toulouse |
2023-03-18 | |
|
| Fort Collins | A Synesthete’s Atlas – Eric Theise & Brett Darling
(aka Spider Lights) |
2023-03-19 | |
|
| 左京区 |
うさぎの神社をデジタルアーカイブ!
|
2023-03-19 | |
|
| Grenoble | Découverte d’OpenStreetMap |
2023-03-20 | |
|
| Lyon | Réunion du groupe local de Lyon |
2023-03-21 | |
|
| 161. Treffen des OSM-Stammtisches Bonn |
2023-03-21 | |||
| City of Edinburgh | OSM Edinburgh Social |
2023-03-21 |  |
|
| Lüneburg | Lüneburger Mappertreffen (online) |
2023-03-21 | |
|
| iD monthly meetup |
2023-03-24 | |||
| Nantes | Découverte du projet cartographique OpenStreetMap |
2023-03-25 | |
Note:
If you like to see your event here, please put it into the OSM calendar. Only data which is there,
will appear in weeklyOSM.
This weeklyOSM was
produced by Nordpfeil,
PierZen,
SK53,
SomeoneElse,
Strubbl,
Ted
Johnson, TheSwavu,
derFred.
We welcome link suggestions for the next issue via this
form and look forward to your contributions.






















































 ►
►



![XKCD 2737 by Randall Monroe (Licensed: (CC-by-NC 2.5)[https://creativecommons.org/licenses/by-nc/2.5/])](https://webcf.waybackmachine.org/web/20230305221551im_/https://imgs.xkcd.com/comics/weather_station.png "'Pour one out for precipitation data integrity,' I say, solemnly upending the glass into the rain gauge.")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_as.jpg){kind=link}
{kind=link}
{kind=link}