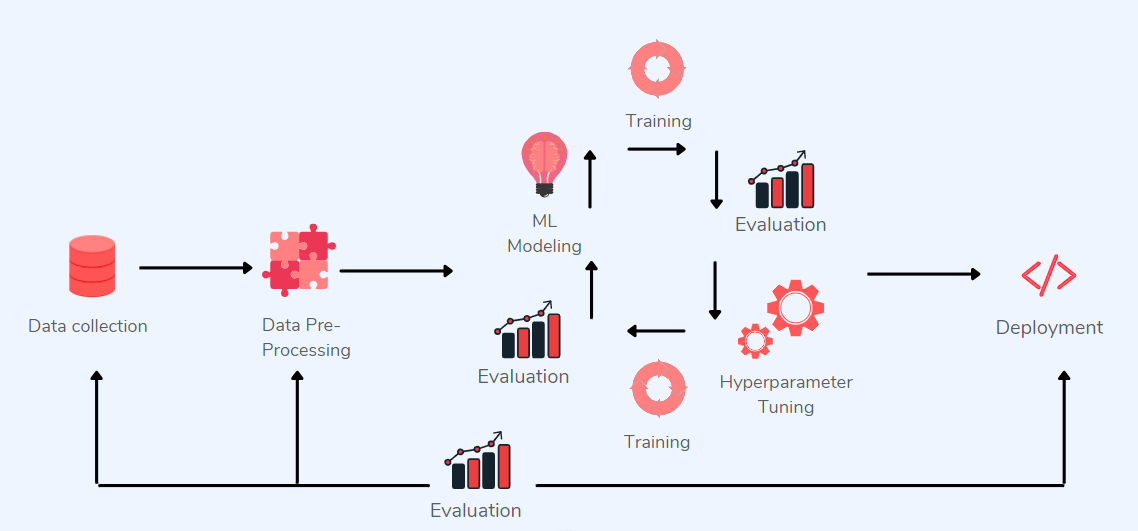
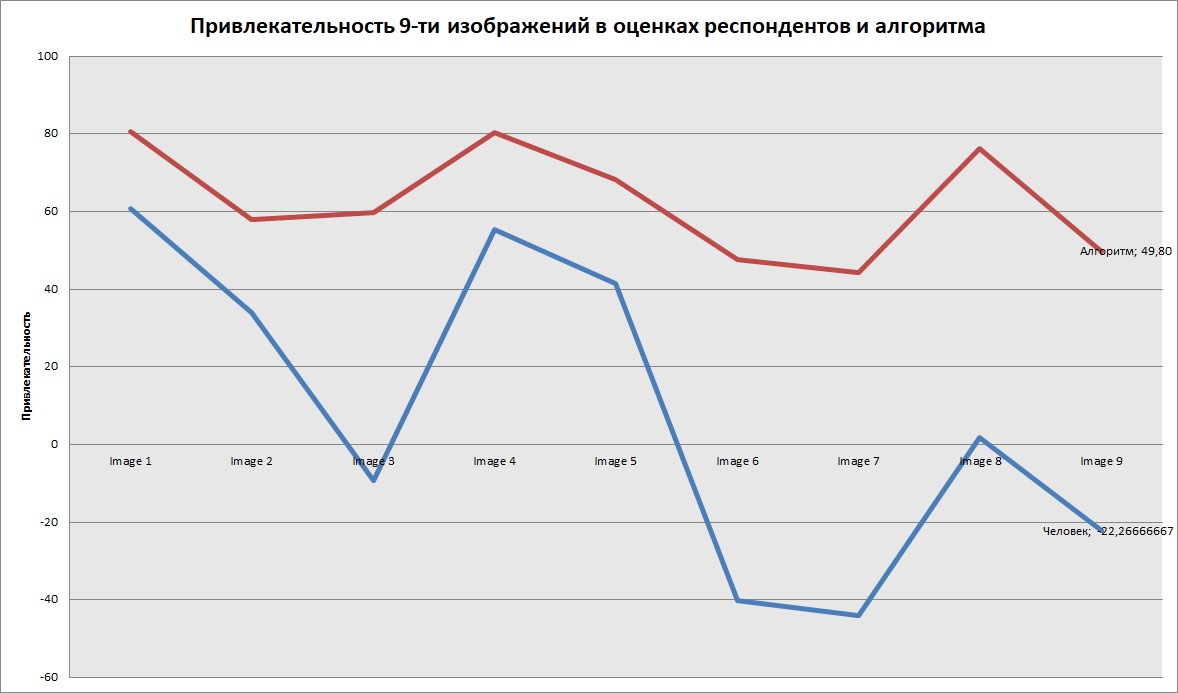
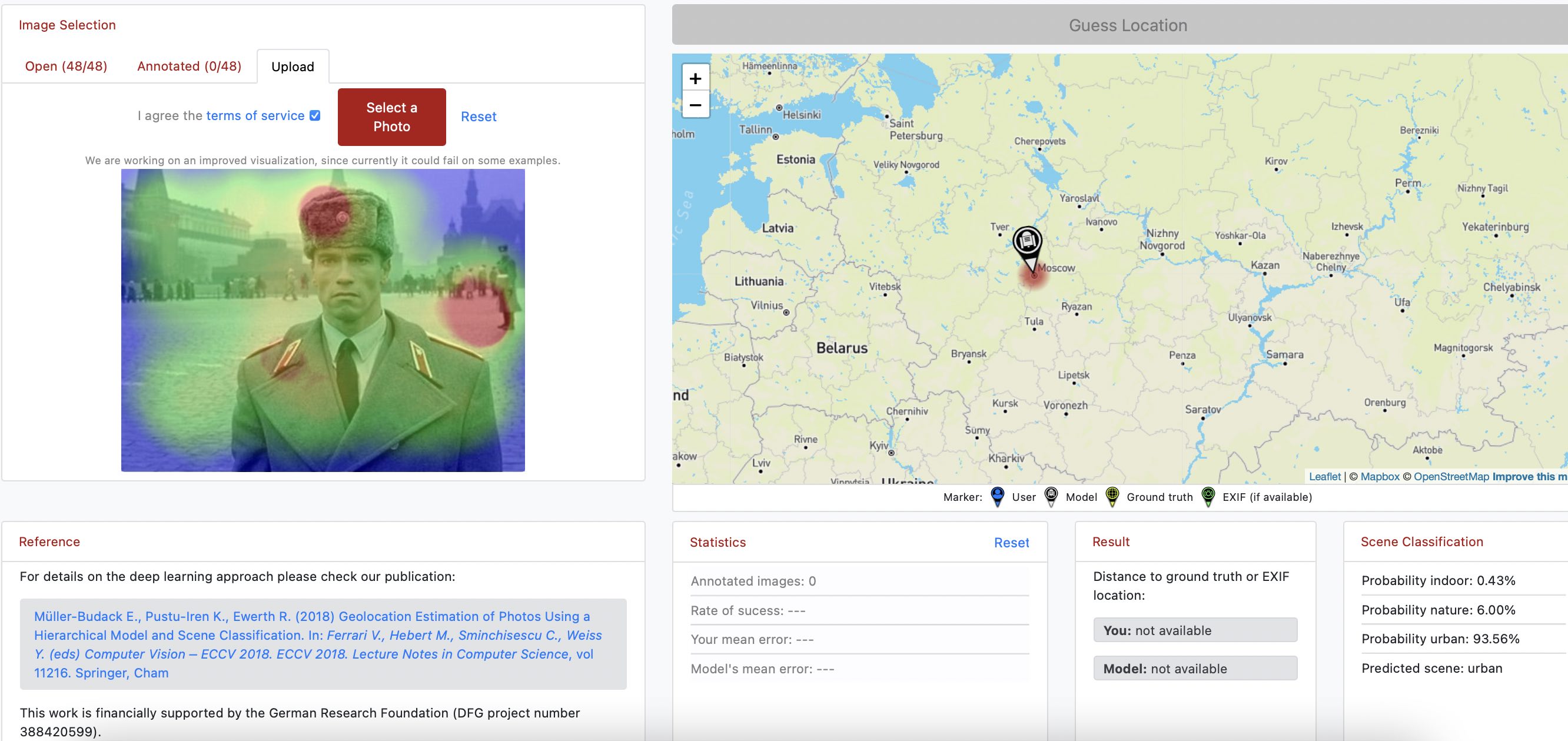
Все чаще для сегментации изображений используется глубокое обучение и сверточные нейронные сети. В случае медицинских картинок достаточно сильно проявляются основные проблемы этого метода: не хватает робастности и интерпретируемости. Происходит это в основном из-за того, что CNN обучаются на текстуре изображения, а не на форме, или требуются дополнительные вычисления post hoc, которые, как было показано, ненадежны с точки зрения интерпретируемости.
В статье SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation авторы предлагают добавить к модели U-Net второй поток данных о форме, а также использовать dual-attention декодер. Такой метод позволил получить очень хорошие результаты на датасетах изображений МРТ сердца SUN09 и AC17, обеспечивая высокую интерпретируемость при различных разрешениях.
Работа опирается на последние достижения в области моделей channel-attention с использованием модулей сжатия и возбуждения, предложенных Hu и др., и spatial attention c оценкой внимания, предложенных Jetley и др..







 В марте 2010 года были популярны в том числе и на Хабре, бесплатные хостинги картинок: собственного сервиса habrastorage.org у сайта ещё не было, а по форумам была довольно популярной услуга — опубликовать картинку на стороннем сервисе и показать её в статье или в комментарии.
В марте 2010 года были популярны в том числе и на Хабре, бесплатные хостинги картинок: собственного сервиса habrastorage.org у сайта ещё не было, а по форумам была довольно популярной услуга — опубликовать картинку на стороннем сервисе и показать её в статье или в комментарии.