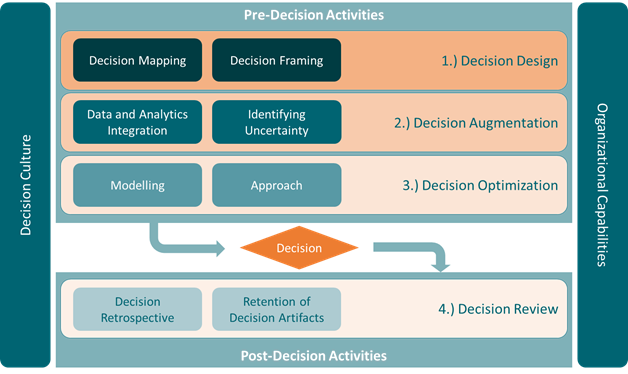
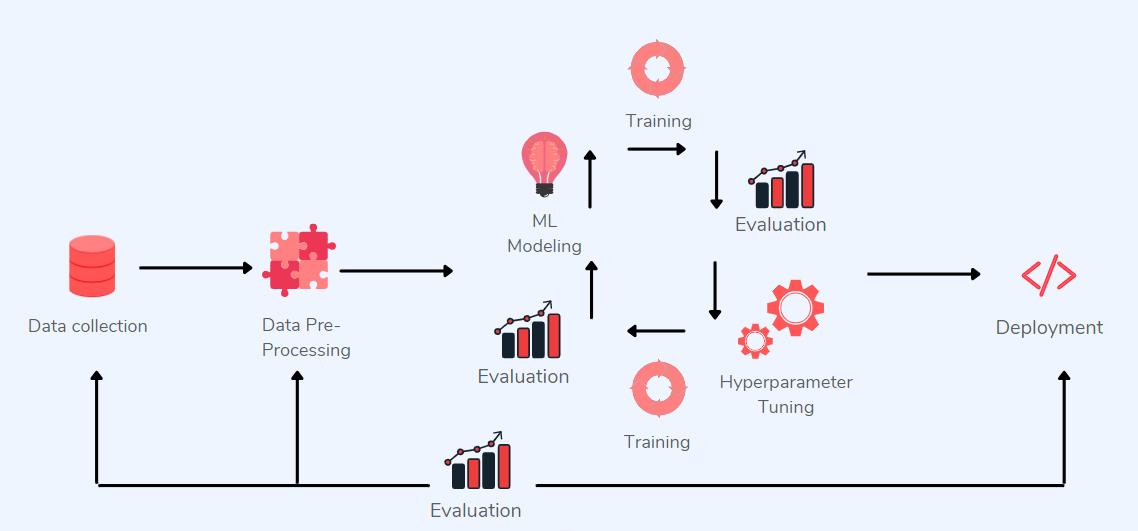
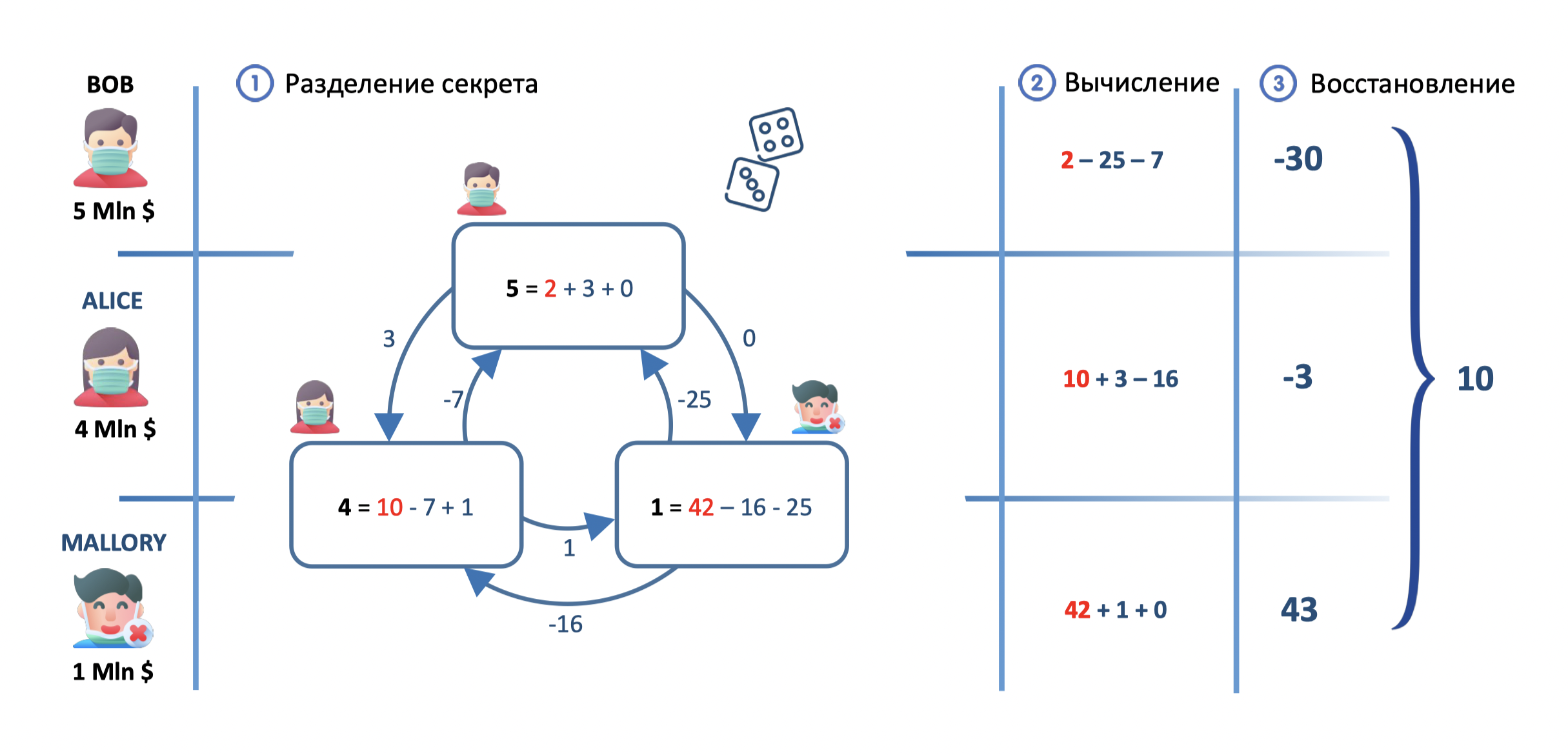
У нас есть несколько способов понимания данных. Зачастую, когда мы анализируем их, то думаем о визуализации в последнюю очередь. Тем не менее, наш разум устроен так, что нам нужна визуальная форма вещей, которые мы хотим исследовать. Поэтому визуализация необходима не только для представления каких-то выводов, но и для выявления закономерностей мира.
Даже работая с некоторой числовой информацией, не относящейся к повседневным вещам, нам часто нужно найти в данных какие-то последовательности и закономерности, чтобы проанализировать их. Если мы увидим картинку, мы сможем сделать это быстрее. Таким образом, основная цель визуализации — создать визуальную форму для лучшего и более эффективного понимания закономерностей, скрытых в данных.
В качестве бонуса: визуализация может иллюстрировать написанные отчеты или статьи для облегчения донесения некоторых идей до читателей.
Тем не менее, данная статья посвящена топу простых видов визуализации. Поэтому с удовольствием поделюсь краткой подборкой вариантов визуализации, которыми пользуюсь почти каждый день.