

К страту курса по автоматизированному тестированию на Python делимся материалом о том, насколько вредным может стать привыкание к библиотекам и насколько полезными — инструменты автоматизированного тестирования. За подробностями приглашаем под кат.
К страту курса по автоматизированному тестированию на Python делимся материалом о том, насколько вредным может стать привыкание к библиотекам и насколько полезными — инструменты автоматизированного тестирования. За подробностями приглашаем под кат.

«Умный в гору не пойдёт, умный гору обойдёт». Примерно так рассуждали DS-специалисты при решении задачи, требующей вычисления 10+ млн расстояний между парами точек по их географическим координатам.

Для визуализации интерактивных карт рассмотрим библиотеку - Folium.
Folium — это мощная библиотека визуализации данных в Python, которая была создана в первую очередь для того, чтобы помочь людям визуализировать гео-пространственные данные.
Folium - это библиотека с открытым исходным кодом, созданная на основе возможностей Datawrangling экосистемы.
С помощью Folium можно создать карту любого местоположения в мире, если вы знаете его значения широты и долготы.
Также можете создать карту и наложить маркеры, а также кластеры маркеров поверх карты для крутых и очень интересных визуализаций.
Folium - это библиотека Python, которая помогает создавать несколько типов карт Leaflet. Тот факт, что результаты Folium интерактивны, делает эту библиотеку очень полезной для создания информационных панелей.
На официальной странице документации Folium:
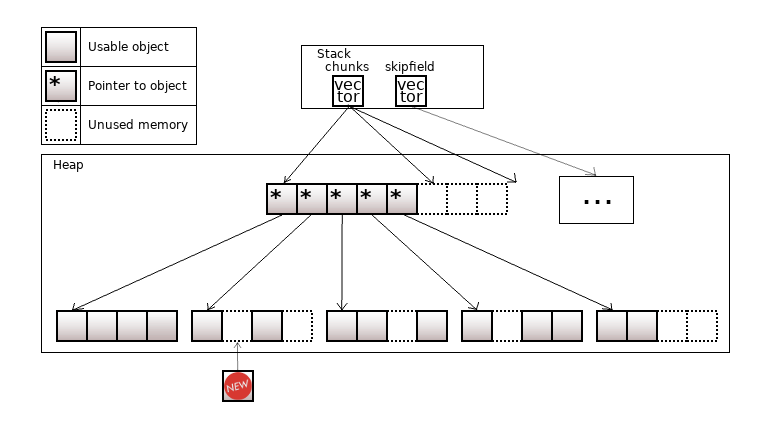
Контейнер - это объект, используемый для хранения других объектов. Контейнер берет на себя управление всей памятью, которые эти объекты занимают.
В стандартную библиотеку C++ входит несколько контейнеров. Кроме этого, в Open Source есть несколько контейнеров, которые покрывают больше юзкейсов. Я опишу устройство интересных контейнеров вне STL и их отличия от классических контейнеров.


Реализовать запись и проигрывание аудиофайлов в iOS несложно. Но если к этому добавляется задача визуализировать звук в момент записи с микрофона, это может вызвать сложности даже у опытного программиста, который мало работал с AVFoundation — мультимедийным фреймворком для работы с аудиовизуальными носителями.
В статье расскажу, как в iOS нативно визуализировать голос в процессе записи и проведу краткий экскурс в физику звукозаписи.

Сегодня принимают поздравления с профессиональным праздником некоторые гики =), так что хотелось бы рассказать о создании чего-то такого теплого светодиодного радиотехнического… И да! для вечного живого Z80!
Кому интересно, что ещё можно такого придумать для Z80 в XXI веке, прошу под кат...

Цель этой статьи — изучить известные факты о грядущем расширении модели многопоточности Java.
Нет, не беспокойтесь, текущая модель многопоточности Java остается, но за кулисами что-то хорошее уже стучится в виртуальную дверь.
Да, мы говорим о JEP-425: Virtual Threads.

Это — специализированный протокол для инкрементального обновления ПО с минимальными задержками. Расскажем, как он устроен, и кто его использует.


Привет, Хабр.
Меня зовут Леонтий. Я уже немного рассказывал тут о себе и своих экспериментах по программированию, которыми я увлекаюсь с младших классов. А еще я увлекаюсь наукой, робототехникой и рисованием.
В этой статье я хочу рассказать о роботе POMPO, которого я придумал, когда мне было 12 лет. Тогда же я выложил его на Behance и получил награду «Лучший дизайн персонажа».
С тех пор я многому научился и теперь я собираюсь построить настоящего боевого робота и участвовать в шоу BattleBots. Деньги на это я планирую заработать с помощью NFT.
Дальше я расскажу о процессе создания NFT-коллекции, о трудностях, о продвижении, покажу свои расчёты и расскажу о том, как будут дорожать в будущем мои NFT и как я планирую развивать проект. Буду рад и поддержке, и замечаниям, которые помогут мне с проектом.

Привет! Я давно заметил, что процесс добавления нового кода в проект в большинстве команд может быть не всегда стандартизирован. Из-за этого могут возникнуть сложности с коммуникациями разработчиков как на уровне описания добавленного кода, так и понимания, какое влияние несет новый функционал на сам проект. Кроме того, команде аналитиков, разработчиков и заказчикам проекта важно иметь описание хронологии изменений проекта в читабельном виде.
Поэтому решил написать статью, в которой хотелось бы затронуть тему стандартизации процесса, используя конвенции и различные инструменты, позволяющие соблюсти правильное и понятное развитие кода проекта, что и применяется в нашей компании. Статья может быть полезна всем тем, кто ведет проекты в git.

Недавно понадобилось мне подключить мой проект (сайт на WordPress, Телеграм-канал, ВК группу) к фильтру матов и озадачился я предложениями, которые выдает интернет. Поэтому решил проанализировать те, что смог найти и составить личный список, который, надеюсь поможет коммунити Хабра.
 В инете полно списков мудрых вдохновляющих цитат. Это всё здорово, но порой скучновато. Представляешь себе, как человек морщит лоб, изо всех сил делает одухотворённое лицо и выдаёт идеальную шедевральную мысль. Скукота.
В инете полно списков мудрых вдохновляющих цитат. Это всё здорово, но порой скучновато. Представляешь себе, как человек морщит лоб, изо всех сил делает одухотворённое лицо и выдаёт идеальную шедевральную мысль. Скукота.
Мне больше нравится, когда люди, на которых все равняются или идеализируют их идеи, внезапно в каком-то высказывании показывают себя с очень практической или человеческой стороны. Или подсвечивают особенности другой эпохи. После чего в голове наступает некоторое просветление.
Кент Бек, создатель методологии "Разработка через тестирование" (TDD), как-то написал:
"Мне платят за работающий код, а не за тесты, поэтому моя философия заключается в том, чтобы тестировать настолько мало, насколько это возможно, чтобы достичь заданного уровня уверенности".
(источник)

Эта статья предназначена для тех, кто уже имеет начальный уровень работы с GIT и BitBucket. В статье рассматриваются примеры в Git Bash version 2.33.0, API BitBucket 2.0, https://bitbucket.org

Грокаем алгоритмы. Иллюстрированное пособие для программистов и любопытствующих от Бхаргава А. Эта книга рекомендована Яндекс Практикум при подготовке к алгоритмическому собеседованию. Сам автор указывает, что книга для самоучек, студентов, выпускников и тех, у кого программирование не является основным профилем.
Мое впечатление неоднозначно. С одной стороны, до сего момента я не встречал описания динамического программирования, поиска кратчайшего пути в графе по алгоритму Дейкстры и использование K ближайших соседей для классификации и аппроксимации (возможно, все это есть в 4м или последующих томах Кнута, но в магазине они мне не встречались). С другой стороны, описания и примеры, приведенные в книге, таковы, что практической пользы не представляют. Описания очень поверхностны, примеры нарочно примитивны, код в половине случаев не приведен. Но даже там где есть код, он нарочито упрощен под конкретный пример и на практике бесполезен.
Казалось бы, есть масса книг - каталогов шаблонов. Они реально полезны и новичку и профессионалу. Эта книга не из их числа. Но, видимо, это и не было целью. Напоминает научно-популярные книги издававшиеся в СССР: простым языком рассказывает о сложных вещах, прививает у читателя интерес к теме, расширяет кругозор. Не более. Но тоже важно.
Вернемся к Яндекс Практикум и их рекомендации. Если алгоритмы так важны, то почему именно эта книга? Есть масса других, где и алгоритмов больше и разобраны они так, что бери да пользуй. Например, классический труд Д. Э. Кнута Искусство программирования. Да, рисунки в детском стиле в Грокаем алгоритмы забавны. Но иллюстрации в Искусство программирования полезны для понимания. Разве это не важнее, если уж кандидата посылают на алгоритмическое собеседование?

Эта статья призвана резюмировать приобретенные знание полученные в процессе обучения программированию. Так вышло, что я попал на обучение на программиста, скажем так, "по-взрослому". Поэтому первым языком стал Си. Основы языка дались легко благодаря опыту работы с языками программирования PHP, JavaScript, C# и Python. Но позднее процесс обучения вышел на новый уровень, связанный со структурами данных. И начались мои страдания.
Оказалось, что моего опыта "кодинга" всякой мелочи недостаточно, опытные пользователи бы сказали, что в интернете существует множество статей по реализации тех же списков, но они мне не подходили. В конечном итоге до всего пришлось доходить самостоятельно, лишь используя имеющиеся статьи. Теперь в этой серии статей я попытаюсь зафиксировать свой опыт. Я всего лишь еще учусь, поэтому в решениях возможны некорректность в реализации, поэтому советам по улучшениям буду рад. А быть может мои статьи помогут еще кому-нибудь.
В чем особенность этих статей? Как говорят еще в научном сообществе -- актуальность, новизна. Каждое решение будет ориентированно и оптимизировано на работу с большим объемом данных. И по крайней мере я попытаюсь так сделать. Все задачи будут решены с использованием языка Си. Статей будет несколько, каждая будет посвящена одному конкретному решению и его реализации. В каждой статье оставлю ссылки на другие, по другим решениям.
Условия реализации следующие. Все программы будут реализовываться для работы в ОС Ubuntu. Возможен их запуск в Unix-подобных системах. Другие специфические особенности будут мной указаны непосредственно в самой статье по конкретному решению.

Все в Python – это объект. Каждый новичок должен сразу усвоить, что все объекты в Python могут быть либо изменяемыми (мутабельным), либо неизменяемыми (иммутабельным).

Существует множество проверенных решений, основанных на разных алгоритмах. Этот пример использует элементы машинного обучения, текущий уровень развития инструментов, позволяет с минимальными усилиями решать "бытовые задачи". В качестве меры сходства - косинусное сходство. Сравнение многомерных массивов (изображение в цифровом пространстве), ресурсоемкий процесс, поэтому, применяем обученную свёрточную нейронную сеть для уменьшения размерности с учетом важных пространственных признаков. Библиотека keras содержит готовые модели под разные задачи, этот пример задействует архитектуру VGG16 обученную на данных imagenet. Вход в сеть (N, 224, 224, 3), выход (1, 512).

Привет, Хабр!
Меня зовут Василий Материкин, я — Android-разработчик в QIWI. В этом посте я расскажу о применении фича-флагов в QIWI Кошельке.
Внедрение Trunk-Based Development и Feature Flags
В процессе работы над большими приложениями, в которых много фич и над которыми трудится большая команда разработчиков, часто приходится сталкиваться с такой проблемой как конфигурация приложения помощью фича-флагов. Мы в QIWI столкнулись с этим два года назад, когда в QIWI Кошельке было создано несколько feature-команд. Выяснилось, что разрабатывать новые фичи с помощью стандартных feature-веток не так удобно, потому что когда над одним проектом работает несколько feature-команд, ветки становятся достаточно объёмными. Потом смержить их в мастер становится довольно непростой задачей, появляются постоянные конфликты.
Поэтому мы решили перейти на Trunk-Based Development (TBD). TBD предлагает работать в небольших ветках и, желательно, чтобы они как можно быстрее были влиты основную ветку. Для этого, конечно же, реализацию нового функционала нужно оформлять небольшими пулл-реквестами, чтобы они быстро проходили ревью и были влиты в основную ветку. Это, в свою очередь, создает другую проблему — когда в главной ветке может появиться код, который ещё не готов к релизу, но при этом нам нужно как-то релизить с этим кодом приложение. Мы же релизы выпускаем достаточно часто. И для этого TBD предлагает пользоваться такими подходами, как Branch by Abstraction (BBA) и Feature Flags (FF).
BBA позволяет выделить какой-либо функционал в отдельную абстракцию. Для этого создается интерфейс, который описывает контракт для работы с этим функционалом. Сразу же можно создать его текущую реализацию, просто скопировав код, который сейчас в продакшене. Также создается другая реализация (уже с новым функционалом) и с ней уже начинается работа. То есть обычно первый пулл-реквест при работе с фичей — это выделение кода, создается две реализации, эти изменения вливаются в главную ветку и далее продолжаем работать уже над новой реализацией. При этом в проекте (в продакшене) используется всё ещё старая реализация, пока мы не закончим работать над фичей.