We thought about building the infrastructure for large load tests a year ago when we reached the mark of 12,000 simultaneously active online users. In three months, we made the first version of the test, which showed us the limits of the service.
The irony is that simultaneously with the launch of the test, we reached the limits on the production server, resulting in two-hour service downtime. This further encouraged us to move from making occasional tests to establishing an effective load testing infrastructure. By infrastructure, I mean all tools for working with load testing: tools for launching the test (manual and automatic), the cluster that creates the load, a production-like cluster, metrics and reporting services, scaling services, and the code to manage it all.
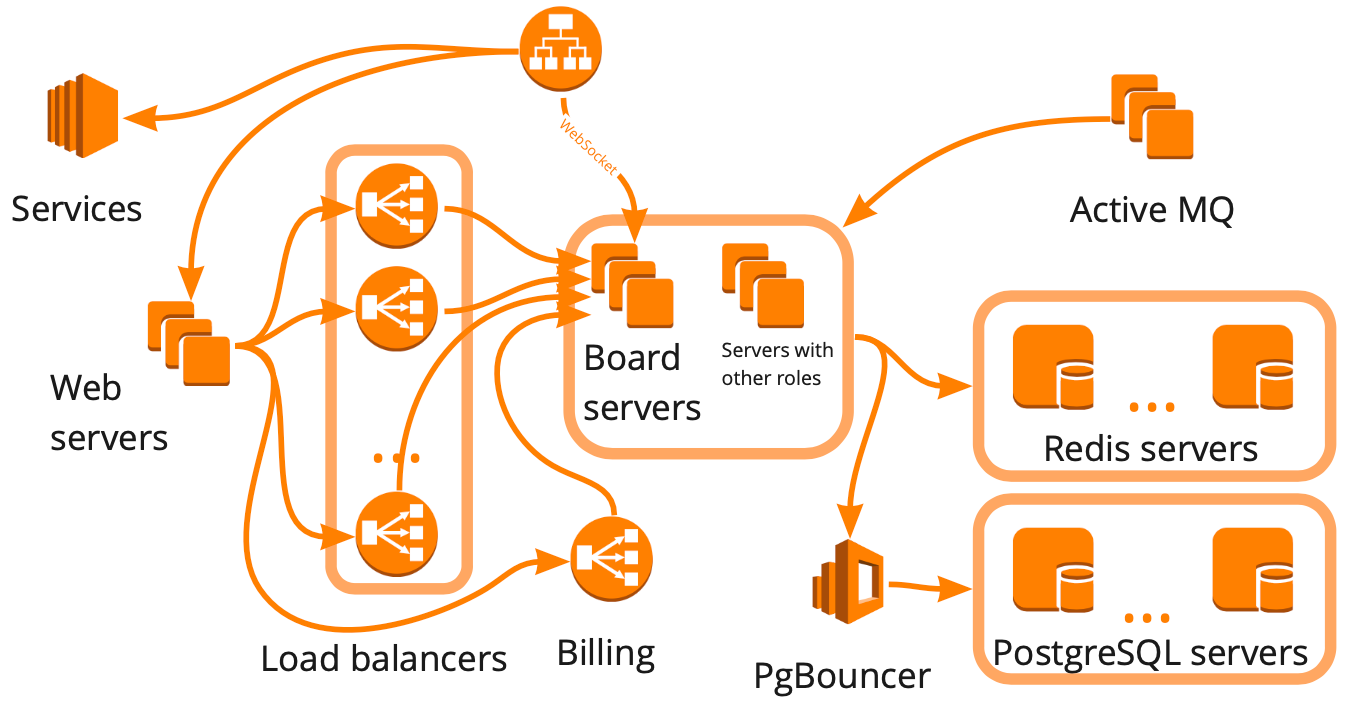
Simplified, this is what our structure looks like: a collection of different servers that somehow interact with each other, each server performing specific tasks. It seemed that to build the load testing infrastructure, it was enough for us to make this diagram, take account of all interactions, and start creating test cases for each block one by one.
This approach is right, but it would have taken many months, which was not suitable for us because of our rapid growth — over the past twelve months,
we have grown from 12,000 to 100,000 simultaneously active online users. Also, we didn’t know how our service infrastructure would respond to the increased load: which blocks would become the bottleneck, and which would scale linearly?









 Talking to people at conferences and in comments to articles, we face the following objection: static analysis reduces the time to detect errors, but takes up programmers' time, which negates the benefits of using it and even slows down the development process. Let's get this objection straightened out and try to show that it's groundless.
Talking to people at conferences and in comments to articles, we face the following objection: static analysis reduces the time to detect errors, but takes up programmers' time, which negates the benefits of using it and even slows down the development process. Let's get this objection straightened out and try to show that it's groundless.



