The release of GNOME 42 (and the Maps release accomplishing it) is due in a little over a week.
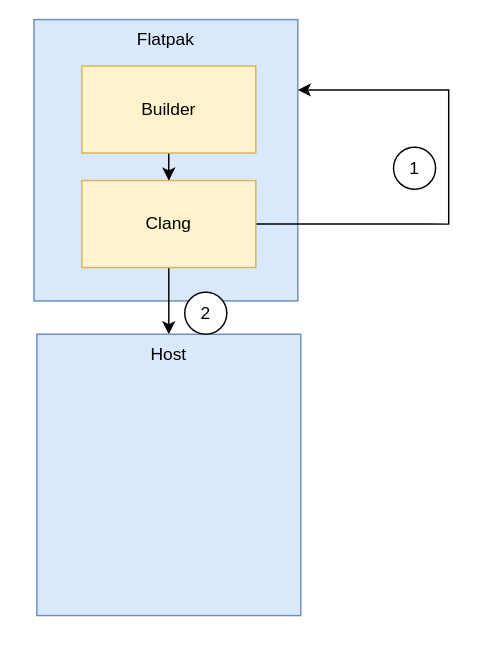
I have already covered some of the more visible updates for Maps 42.0 in the last update, such as the development profile (allowing to run directly from GNOME Builder, or install “nightly” Flatpak builds, and be able to run them in parallel with a stable release (distinguished by it's icon overlay and headerbar styling).
Also we have the support for handling the maps: URI scheme, allowing to open search queries from other programs. This feature will already be utilized by GNOME Contacts for opening locations of contacts in your address book when they have a physical address set.
Some of the last changes involves utilizing the “tabular numbers” Pango font feature attribute, to get the time labels to align up vertically (even when the system font has variable-width digits) when rendering public transit itineraries.
Also, we have revised screenshots prepared by Sofie Herold, linked in the “appdata“ metadata to show in software centers like GNOME Software.
Another small attention to detail that I included pretty late, is that now the state of showing the scale (which can be toggled with the ctrl+s shortcut) is now stored in gsettings and remembered between runs (rather than always showing when you start next time, if you choose to hide it).
Unfortunalty, I totally forgot that adding new gsettings schema keys also means adding new strings for translation (the descriptions), so I accidentally broke the “string freeze” break (which started after the 42.beta release). So I had to retroactively ask for an exception.
Pika Backup gained an improved sense of what’s going on with its running BorgBackup processes. In turn, this allows Pika to show more information in the user interface about what’s currently going on.
The mechanism also provides the basis for implementing missing features like stopping scheduled backups if the used connection becomes metered or the computer runs on battery for a while. Parts of those features are already implemented.
This week, Audio Sharing joined GNOME Circle. Audio Sharing can stream your PC’s audio to your phone and therefore can, for example, allow you to use audio hardware that only connects to your phone. Congratulations!
Core Apps and Libraries
Vala
An object-oriented programming language with a self-hosting compiler that generates C code and uses the GObject system
There is now a Sdk extension with the Vala compiler, language server and other tooling on flathub! You can compile your Vala app with it, or use the tools and libraries in your application. Thanks to Bilal Elmoussaoui for help.
A Software Bill of Materials (aka SBoM) is something you’ve probably never heard of, but in future years they’ll hopefully start to become more and more important. In May last year the US president issued an executive order titled Improving the Nation’s Cybersecurity in which it outlines the way that critical software used by various branches of the government should be more traceable and secure. One of the key information captured in a SBoM is “who built what from where” which in open source we’re already familiar with, e.g. “Red Hat built your Linux kernel in a datacenter in the US” rather than “random person from the internet build your container on their laptop using Debian Sarge” and in the former case we also always have the hash of the source archive that was used to build it, and a lot more. Where this concept breaks down is firmware, where lots of different entities build each subsection in different ways, usually due to commercial and technical constraints.
Firmware is often lumped together as one thing, both technically as-in “one download” and conceptually when thinking about OS security. In reality a single firmware image might contain a FSP from Intel, several updated CPU microcode blobs for a few different CPUs, a CSME management engine, an embedded controller update, a UEFI system firmware a lot more. The system firmware is then made up of different file volumes, each with a few dozen EFI “PEI” binaries for initial system start-up and then a couple of hundred (!) “DXE” binaries for things like pre-boot networking and things like fingerprint authentication, mouse and keyboard input.
In the executive order from last May, firmware was explicitly excluded from the list of software that required a SBoM, on the logic that none of the infrastructure or specifications were in place, and it just wasn’t possible to do. The requirement for SBoM for boot-level firmware is expected in subsequent phases of the executive order. Needless to say I’ve been spending the last few months putting all the pieces together to make a firmware SBoM not just possible, but super easy for OEMs, ODMs and IBVs to generate.
The first problem to solve is how to embed the software ID (also known as SWID) metadata into each EFI binary. This is solved by putting coSWID metadata (a DTMF specification) into a new COFF section called, unsurprisingly, “SBOM”. This allows us to automatically capture at build time some data, for instance the tree hash, and the files that were used to build the binary, etc. This is what my friends at Eclypsium have been working on – so soon you can drop a top-level vendor.ini file in your EDK2 checkout with the correct vendor data (legal name, home page etc.) and then you can just build the tree and get everything inserted in this new PE section automatically. This gets us half way there. The uSWID readme explains how to do this manually too, for people not using either the EDK2 build-system or a variant of it.
The second problem is how to include SWID metadata for the blobs we either don’t build, or we can’t modify in any way, e.g. the FSP or uCode. For this there’s an “external” version of the same coSWID metadata which has a simple header we can find in the firmware image. This can either be included in the file volume itself, or just included as a file alongside the binary deliverable. We just have to trust that the vendor includes the correct metadata there – and we’re already trusting the vendor to implement things like SecureBoot correctly. The vendor can either use the [pip install] uswid command line (more examples in the uSWID readme) or more helpfully there’s also a web-generator on the LVFS that can spit out the tiny coSWID blob with the correct header ready to be included somewhere in the binary image.
Open source firmware like coreboot is also in the same boat of course, but here we have more flexibility in how to generate and include the SWID metadata in the image. My friends at Immune and 9elements are planning to work on this really soon, so we can have feature parity for free firmware like coreboot – even when non-free blobs are included into the image so that it can actually work on real hardware.
So, we have the metadata provision from the IBV, ODM and OEM all sprinkled around the update binary. What do we do then? When the binary is uploaded to the LVFS we decompress all the shards of the firmware, and do various checks. At this point we can look for coSWID metadata in the EFI binaries and also uSWID+coSWID metadata for the non-free blobs. From this we can save any of the detected SWID metadata to the per-component datastore, and make it available as a publicly available SBoM HTML page and also .zip archive containing the raw SWID XML data. It probably makes sense to have an external tool, either a CLI utility in the lvfs-website project, or something in native golang — but that doesn’t exist yet.
The vendor also gets the all important “green tick” which means the customer buying the hardware knows that it’s complying with the new requirements. Of course, we can’t check if the ODM has included all the SWID metadata for all the binaries, or included all the SWID components for all of the nonfree chunks, but it’s good enough as a first pass. The next logical thing would be to make a rule saying that the SWID green tick disappears if we detected CPU microcode, but also didn’t detect any microcode SWID metadata, etc. It would also be interesting to show a pie-chart for a given firmware image, showing just where the firmware has been built from, and who by, and how much stuff remains unaccounted for. But, little steps first.
I think I’ve got agreement-in-principal from most of the major stakeholders, and I’ll be hopefully presenting this work alongside AMI to the UEFI forum in a few months time. This means we’re in a position to actually provide SBoM for all firmware when the next EO revision is announced, rather than the ecosystem collapsing into a ball of raw panic.
If you want to add uSWID metadata to your firmware please let me know how I can help, even if it’s not available on the LVFS yet; I think this makes just as much sense for firmware that sits on a USB hub as it does your system firmware. Comments welcome.
The command-line tools that are part of GnuTLS (such as certtool and p11tool) had been using the GNU AutoGen for handling command-line arguments. AutoGen (do not be confused with autogen.sh script commonly used in Autotools based projects) does a great job in that regard, as it produces command-line parsing code and the documentation from the single source file. On the other hand, integrating the AutoGen infrastructure into a project can be tricky in many ways, e.g., it requires its own runtime library (libopts) whose interface compatibility is not well maintained. Therefore, we decided to switch to a simpler solution and have finallycompleted the migration recently. As I spent way too much time on this, I thought it might make sense to summarize the process in case anyone comes into a similar situation.
The first thing we tried was to define the requirements and review the existing alternatives. The requirements turned out to be:
The tool produces code and documentation from the same source, i.e., we do not need to repeat ourselves writing a separate documentation for the commands
The generated code has little to no run-time dependencies
The tool itself doesn’t have exotic (build-)dependencies
We soon realized that there are surprisingly few candidates that meet those requirements. help2man, which is widely used in GNU tools, generates documentation from the command output, while it only supports manual pages (no texinfo/html/pdf support); neither GNU Gengetopt, gaa, nor argtable supports documentation generation at all, etc.
The other thing to consider was how to implement it in a non-disruptive manner. The initial attempt was to combine a help2man-like approach with documentation format conversion using Pandoc, which seemed good in general but the hurdle was that the AutoGen option definitions are written in its own language. Before proceeding with this approach we need to find a way to convert the definitions into the actual option parsing code!
We split this task into two phases: first to parse the AutoGen definitions and convert it to an easier-to-use format such as JSON and YAML, and then process it to generate the code. For the former, I came across pest.rs, which is a PEG (parsing expression grammar) based parser generator with elegantly designed programming interface in Rust. With this I was able to write a converter from the AutoGen definitions to JSON.
Then the generated JSON files are processed by Python scripts to generate the code and documentation. As the first phase is one-shot, we do not need Rust at build time but only need the Python scripts and its dependencies to be integrated in the project.
The scripts and the JSON schema are now hosted as a separate project, which might be useful for other projects.
No, I mean the digital ones, meant to be opened specifically with Adobe Reader?
Well, in Q4 2021, Mozilla’s PDF.js landed support for XFA PDF forms, so Firefox is now able to deal with them, which is huge deal, as we have been increasingly encountering such documents over the years, and still will be for a long time, especially given how slow-moving governments can be when it comes to their digital practices.
It would be fantastic to see these code insights put to use in Poppler, the library that Evince, Okular and other applications use… so if someone feels like fixing one of the few biggest issues with reading/filling PDFs under Linux, please use this code (see also: all the XFA-related pull requests) as inspiration to contribute a fix to this and that issue in Poppler!
Of course, there are remaining issues related to forms in PDF.js, but it’s still better than nothing; and perhaps your efforts in replicating this functionality into Poppler can lead to interesting cross-project findings that can also benefit the PDF.js project?
We are happy to announce that GNOME has been accepted as a mentor organization for Google Summer of Code 2022!
New contributors will be reaching out in our communication channels for information about the program and to discuss project ideas, please point them to gsoc.gnome.org.
A quick reminder: libei is the library for emulated input. It comes as a pair of C libraries, libei for the client side and libeis for the server side.
libei has been sitting mostly untouched since the last status update. There are two use-cases we need to solve for input emulation in Wayland - the ability to emulate input (think xdotool, or Synergy/Barrier/InputLeap client) and the ability to capture input (think Synergy/Barrier/InputLeap server). The latter effectively blocked development in libei [1], until that use-case was sorted there wasn't much point investing too much into libei - after all it may get thrown out as a bad idea. And epiphanies were as elusive like toilet paper and RATs, so nothing much get done. This changed about a week or two ago when the required lightbulb finally arrived, pre-lit from the factory.
So, the solution to the input capturing use-case is going to be a so-called "passive context" for libei. In the traditional [2] "active context" approach for libei we have the EIS implementation in the compositor and a client using libei to connect to that. The compositor sets up a seat or more, then some devices within that seat that typically represent the available screens. libei then sends events through these devices, causing input to be appear in the compositor which moves the cursor around. In a typical and simple use-case you'd get a 1920x1080 absolute pointer device and a keyboard with a $layout keymap, libei then sends events to position the cursor and or happily type away on-screen.
In the "passive context" <deja-vu> approach for libei we have the EIS implementation in the compositor and a client using libei to connect to that. The compositor sets up a seat or more, then some devices within that seat </deja-vu> that typically represent the physical devices connected to the host computer. libei then receives events from these devices, causing input to be generated in the libei client. In a typical and simple use-case you'd get a relative pointer device and a keyboard device with a $layout keymap, the compositor then sends events matching the relative input of the connected mouse or touchpad.
The two notable differences are thus: events flow from EIS to libei and the devices don't represent the screen but rather the physical [3] input devices.
This changes libei from a library for emulated input to an input event transport layer between two processes. On a much higher level than e.g. evdev or HID and with more contextual information (seats, devices are logically abstracted, etc.). And of course, the EIS implementation is always in control of the events, regardless which direction they flow. A compositor can implement an event filter or designate key to break the connection to the libei client. In pseudocode, the compositor's input event processing function will look like this:
function handle_input_events(): real_events = libinput.get_events() for e in real_events: if input_capture_active: send_event_to_passive_libei_client(e) else: process_event(e)
emulated_events = eis.get_events_from_active_clients() for e in emulated_events: process_event(e)
Not shown here are the various appropriate filters and conversions in between (e.g. all relative events from libinput devices would likely be sent through the single relative device exposed on the EIS context). Again, the compositor is in control so it would be trivial to implement e.g. capturing of the touchpad only but not the mouse.
In the current design, a libei context can only be active or passive, not both. The EIS context is both, it's up to the implementation to disconnect active or passive clients if it doesn't support those.
Notably, the above only caters for the transport of input events, it doesn't actually make any decision on when to capture events. This handled by the CaptureInput XDG Desktop Portal [4]. The idea here is that an application like Synergy/Barrier/InputLeap server connects to the CaptureInput portal and requests a CaptureInput session. In that session it can define pointer barriers (left edge, right edge, etc.) and, in the future, maybe other triggers. In return it gets a libei socket that it can initialize a libei context from. When the compositor decides that the pointer barrier has been crossed, it re-routes the input events through the EIS context so they pop out in the application. Synergy/Barrier/InputLeap then converts that to the global position, passes it to the right remote Synergy/Barrier/InputLeap client and replays it there through an active libei context where it feeds into the local compositor.
Because the management of when to capture input is handled by the portal and the respective backends, it can be natively integrated into the UI. Because the actual input events are a direct flow between compositor and application, the latency should be minimal. Because it's a high-level event library, you don't need to care about hardware-specific details (unlike, say, the inputfd proposal from 2017). Because the negotiation of when to capture input is through the portal, the application itself can run inside a sandbox. And because libei only handles the transport layer, compositors that don't want to support sandboxes can set up their own negotiation protocol.
So overall, right now this seems like a workable solution.
[1] "blocked" is probably overstating it a bit but no-one else tried to push it forward, so.. [2] "traditional" is probably overstating it for a project that's barely out of alpha development [3] "physical" is probably overstating it since it's likely to be a logical representation of the types of inputs, e.g. one relative device for all mice/touchpads/trackpoints [4] "handled by" is probably overstating it since at the time of writing the portal is merely a draft of an XML file
Chris 🌱️ and I launched the Update App Screenshots Initiative. Our short-term goal is to have up-to-date screenshots for all Core apps for the upcoming GNOME 42 release. So far, for 15 of 30 Core apps, merge requests are created or already merged.
If you are maintaining or contributing to an app, you can have a look at our screenshot guidelines, and if needed update your screenshots accordingly.
I have released an updated version of “Audio Sharing”. The interface has been adapted to the new Adwaita design, and some bugs that prevented streaming have been fixed.
In case you don’t know it yet - with this small tool you can stream the audio playback from your computer to other devices in your local network.
You can find a more detailed description on the project homepage. It is available for download on Flathub.
The Getting Started tutorial for newcomers to GNOME application development is now complete. You can follow it to learn how to use GNOME Builder to write your own GNOME application; loading and saving content with asynchronous operations; changing the style of your application; adding menus; and saving preferences. The documentation is ready for GNOME 42 and libadwaita: https://developer.gnome.org/documentation/tutorials/beginners/getting_started.html
The Desktop-Cube extension for GNOME Shell has been updated and brings many new features! Most importantly, you can now freely rotate the cube by click-and-drag. This works in the overview, on the desktop, and on the panel. The latter is especially cool if you have a maximized window!
Cockpit CI demands Testing Cockpit is not an easy task – each pull request gets tested by over 300 browser integration test cases on a dozen operating systems. Each per-OS test suite starts hundreds of virtual machines, and many of them exercise them quite hard: provoking crashes, rebooting, attaching storage or network devices, or changing boot loader arguments.
With these requirements we absolutely depend on a working /dev/kvm in the test environment, and a performant host to run all these tests in a reasonable time.
Yes, ladies, gentlemen, and seemingly-dead plants, it’s happening: after over 10 months of incremental work from the community, we are now releasing version 0.6 of our favorite personal productivity app, Getting Things GNOME. This release comes with some new features, lots of code improvements, many bugfixes and UX refinements (I am told that the “Better procrastination button”, presented below, deserves a place in the Museum of Modern Art).
Save the children, and the parents… tasks.
GTG 0.6 includes fixes for a long-standing higgs-bugson crasher, that would happen under some unpredictable conditions (such as issue 595 and issue 724) and was therefore hard to reproduce for a long time… until I hit the point, in my chaotic 2021 year, where I had accumulated over 2500 tasks as I forgot to clean my closed tasks for a few months… when your data file is that big, the bug becomes much easier to trigger.
We also fixed this mandelbug that would make GTG show inconsistent results in the list of tasks, under some circumstances. Neui was able to deduce the cause for the problem by looking at the tracebacks, and provided a fix in liblarch. GTG 0.6 will therefore require an updated version of liblarch.
Those two deeply nested bugs are the reason why I’m officially codenaming this release… “Shin Kidō Senki GTG Wing: Endless Recursion”.
Hey, we have a new synchronization backend now! If you have a CalDAV server (for example, something with OwnCloud or YUNOHOST), you can use this to synchronize GTG across your multiple computers.
It’s been a long time in the works. I would like to thank Mildred for doing the initial research and coding, then François Schmidts for doing another attempt at coding this feature, and for being very patient with us until we could finally merge this, after a lot of other architectural work landed. I know it can sometimes be tough for new contributors to wait for their code to land in an established open-source project, and for that project to also release the code in a stable release.
(With apologies to Mildred, François, and Padmé.)
Check out the built-in user manual pages to learn how you can use the CalDAV sync feature. There’s an online copy of the user manual, too. So far nobody reported catastrophic failures, so this sync backend seems to be Enterprise Ready™, but if you do encounter issues related to the CalDAV backend, kindly report them (even better if you can help with fixes and refinements!)
Please try out this new feature, and look at the ticket linked above. Do you see additional features that would be good to add? Should they be part of this plugin, or a separate plugin? Let us know.
Modernized tag editor
This is what it used to look like:
This is what it looks like now:
Better procrastination button
One of the most important buttons in my GTG workflow is the “Do it tomorrow” button, and its associated menubutton that lets you reschedule a task’s start date a couple of days into the future. I call that feature the “procrastination” button and this might sound a bit silly, but it really is just an essential way to manage a frequently-changing set of priorities, schedule and obligations, and a way to manage your energy levels.
This release improves this feature with some additional attention to detail:
In issue #550, I detailed the various inconsistencies between this menubutton and the contextual (right-click) menus for deferring tasks. As we were nearing the 0.6 release, I had a “How Hard Can It Be, Really?™” moment and went through a late night coding session to scratch at least part of my design itch, as it had been annoying me for a year by now and I didn’t want to stare at it for another release cycle. So this pull request of mine solves at least one half of the problem, which is probably better than nothing. Anyone is welcome to finish the 2nd half; you might have to harmonize that code with dates.py. Until then, here’s how it looks like now:
Errors will be noticed easily again
GTG used to have a fantastically avant-garde technological feature where it would automatically catch and display Python errors (tracebacks) in the graphical user interface. This feature got lost in what led up to the 0.4 release, but it is now making a comeback in GTG 0.6, thanks to Neui’s fine engineering work. It not only catches tracebacks, but also determines whether they are critical or if the application can possibly continue running. I did some UI & UX refinements on top of Neui’s version, and we now have this honest but still reasonably reassuring dialog:
If you click the expander, you get the traceback, along with some additional information, all neatly MarkDown-formatted so that it can be readily pasted alongside your bug report on modern bug trackers:
Of course, our software is perfect and you should never actually encounter such errors/uncaught exceptions, but… you never know. In the rare cases where this might happen, as a user, it’s better to be made aware if such a problem occurs—and the possibility of the application’s internal state being inconsistent—right when you trigger the issue, so that you can know what sequence of events led to a problem in the code, and report it in our issue tracker.
If you need to test this dialog (ex.: to test translations) but can’t find bugs in our flawless code, you can use GTG’s built-in “Developer Console” to trigger a traceback that will make that dialog appear (see this tip in our documentation).
Tough times, strong community
It’s been a hell of a year, but it’s still been less than a year since 0.5. Ideally we would be on a faster cycle, but we kept merging new and interesting things, and 2021 was pretty intense for many of us, so we slipped a bit.
Diego had to take time off to take care of his family and personal health, and I, certainly like many readers here, had a pretty busy year in my day-to-day work and beyond.
I deeply appreciate the GTG community’s patience in contributing, getting involved and sticking together to improve this project. Personally, I was not able to keep up very closely with all the activity going on; I received somewhere around 1900 emails related to GTG tickets and merge requests during the 0.6 cycle (from April 6th 2021 to this day), so it is clear that the community’s involvement is really strong here, and that’s awesome. If you’re not already part of this, consider joining the fun!
Let me take a minute to dish out some praise here for the fabulous and tireless work of our most frequent contributors. Thank you,
“Neui” for contributing a ton of patches, code reviews, advice, that helped the project’s technical architecture progress steadily throughout the year (also, thank you for investigating some of my craziest bugs and providing solutions for them!) ;
Diego, for plowing through architectural code refactoring, bugfixing, code reviews, during what I know was a difficult time;
Mildred and François, for making the CalDAV sync backend possible.
Mohieddine Drissi for creating the gamification plugin
Danielle Vansia, who not only updated and expanded the user manual so that you could know how the hell to use that CalDAV feature, but also kindly took Diego’s “changes since 0.5” braindump, expanded and polished it into the release notes you can find further below.
…and many other contributors who have made this release possible by providing bug fixes, code quality improvements, etc. They are listed in the about dialog’s credit section for this release, too 😉
Releasing because I can’t stand 0.5 anymore
You know, my gtg_data.xml file is pretty heavy:
No, I mean really heavy:
(Insert Hans Zimmer brass sounds)
As I write this, my data file contains over 2700 tasks (~1800 open, ~700 done, ~ 200 dismissed). The problem is, when you reach that kind of heaviness in your data file, in 0.5 you will encounter not only occasional crashes “when adding a parent/child task or when marking a recurrent task as done” (as mentioned at the beginning of this blog post), but also when trying to delete a bunch of tasks at once… which meant my “purge tasks” feature was not working anymore, which meant I kept piling on hundreds of “closed” tasks every month that I couldn’t easily remove from my tasks data file, which meant performance kept getting worse and crashes were getting more likely…
These are the total number of tasks in my XML file over time (including open, done and dismissed tasks). Each dip is when I tell GTG to purge closed tasks from the file. I know, those numbers keep going back up, higher and higher; I really need to find people to take care of some of my home and infrastructure bullshit, but that’s besides the point 😉
With those issues exacerbated by my “abnormally heavy” data file growing heavier every day, you can imagine that version 0.5 had become unbearable for me in my day-to-day use…
…therefore we have a perfect excuse to release version 0.6, which solves those issues! 😇 “Release when you can’t stand the previous release anymore!”
A new CalDAV backend is available, and the backends dialog is available again. CalDAV is a calendaring protocol that allows a client to access items from a server. GTG now provides support for this standard, and with this new sync service, you can manage all your tasks in one place.
The new “Gamify” plugin adds a game aspect to your GTG workflow, such as the ability to set task targets and task completion streaks.
The Tag Editor was completely redesigned.
Added support for undo/redo actions in the Task Editor.
Added the ability to collapse and expand all tasks in the main menu.
Added the F10 shortcut to open the main menu.
ESC now closes the calendar picker window.
Added the CTRL+B shortcut to set focus on the sidebar.
Added an option to set the due date to “today” in the context menu.
The “Mark as not done” and “Undismiss” actions were replaced by a unified “Reopen” action for closed tasks in the right-click context menu.
The “Start Tomorrow” button is now adaptive, so that the main window can be resized to smaller widths.
The task deferral menubutton (next to “Start Tomorrow”) now shows both weekday names and the offset number of days from today. It also allows easily deferring to 7 days instead of only 6 days, and the ordering of this menubutton matches better with other menus.
Backend, Code Quality, and Performance Improvements:
Reintroduced the global exception/traceback catcher, with a dialog showing up when an error occurs.
Made an improvement to avoid infinite loops when entering invalid dates in the Quick Add entry.
Made an update to prevent errors when no task is selected.
Removed some deprecation warnings.
Added StartupWMClass to make pinning on KDE work.
Used application ID as the window icon (so KDE shows the correct icon).
Made several changes in preparation for Gtk 4.0, as well as updated a number of deprecated GTK-related items.
Made a ton of PEP8 and style fixes.
Refactored the date class.
Updated the ability to render tag icons better on HiDPI.
Updated the anonymize script.
Added gtg://TASK-ID to the command-line help.
Added the -p parameter for profiling in debug.sh.
We migrated from “Nose” to “PyTest” for the test suite, as Nose is unmaintained.
Bug Fixes:
Fixed possible crash when trying to create parent task, and similar operations, when the “Open” tab has not been opened yet (maximum recursion depth error).
Made a change to save a task before creating a parent. This prevents an error that appeared when a task title would be reset after adding a parent.
Fixed an issue where tags were being duplicated.
Fixed an issue where tags and saved searches with the same name were being considered duplicates.
Fixed a bug where every editor window would come back if GTG wasn’t closed cleanly (i.e., shut down).
Made several fixes for scripts.
Fixed certain main menu entries not being selectable via the keyboard.
Fixed the cut-off when you expand the columns too much.
Fixed a regression where symbols in tags (e.g., dashes and dots) were not recognized by the Task Editor. Also, added support for a few more.
Fixed a bug where tags’ icon, parent, and color were not being removed in the XML file.
Fixed a bug that occured when GTG just starts up with no tasks selected, and the user tried to use the “Add Parent” hotkey.
A couple of tough questions for all of you: 1. Is the date 2022-06-01 equal to the time 2022-06-01 12:00:00? 2. Is the date 2022-06-01 between the time 2022-06-01 12:00:00 and the time 2022-12-31 12:00:00? 3. Is the time 2022-06-01 12:00:00 after the date 2022-06-01?
I’ve been involved for two years and counting1 in the design of Temporal, an enhancement for the JavaScript language that adds modern facilities for handling dates and times. One of the principles of Temporal that was established long before I got involved, is that we should use different objects to represent different concepts. For example, if you want to represent a calendar date that’s not associated with any specific time of day, you use a class that doesn’t require you to make up a bogus time of day.2 Each class has a definition for equality, comparison, and other operations that are appropriate to the concept it represents, and you get to specify which one is appropriate for your use case by your choice of which one you use. In other, more jargony, words, Temporal offers different data types with different semantics.3
For me these questions all boil down to, when we consider a textual representation like 2022-06-01, what concept does it represent? I would say that each of these strings can represent more than one concept, and to get a good answer, you need to specify which concept you are talking about.
So, my answers to the three questions are “it depends”, “no but maybe yes”, and “it depends.” I’ll walk through why I think this, and how I would solve it with Temporal, for each question.
You can follow along or try out your own answers by going the Temporal documentation page, and opening your browser console. That will give you an environment where you can try these examples and experiment for yourself.
Question 1
Is the date 2022-06-01 equal to the time 2022-06-01 12:00:00?
As I mentioned above, Temporal has different data types with different semantics. In the case of this question, what the question refers to as a “time” we call a “date-time” in Temporal4, and the “date” is still a date. The specific types we’d use are PlainDateTime and PlainDate, respectively. PlainDate is a calendar date that doesn’t have a time associated with it: a single square on a wall calendar. PlainDateTime is a calendar date with a wall-clock time. In both cases, “plain” refers to not having a time zone attached, so we know we’re not dealing with any 23-hour or 25-hour or even more unusual day lengths.
The reason I say that the answer depends, is that you simply can’t say whether a date is equal to a date-time. They are two different concepts, so the answer is not well-defined. If you want to do that, you have to convert one to the other so that you either compare two dates, or two date-times, each with their accompanying definition of equality.
You do this in Temporal by choosing the type of object to create, PlainDate or PlainDateTime, and the resulting object’s equals() method will do the right thing:
I think either of PlainDate or PlainDateTime semantics could be valid based on your application, so it seems important that both are within reach of the programmer. I will say that I don’t expect PlainDateTime will get used very often in practice.5 But I can think of a use case for either one of these:
If you have a list of PlainDateTime events to present to a user, and you want to filter them by date. Let’s say we have data from a pedometer, where we care about what local time it was in the user’s time zone when they got their exercise, and the user has asked to see all the exercise they got yesterday. In this case I’d use date semantics: convert the PlainDateTime data to PlainDate data.
On the other hand, if the 2022-06-01 input comes from a date picker widget where the user could have input a time but didn’t, then we might decide that it makes sense to default the time of day to midnight, and therefore use date-time semantics.
Question 2
Is the date 2022-06-01 between the time 2022-06-01 12:00:00 and the time 2022-12-31 12:00:00?
I think the answer to this one is more unambiguously a no. If we use date-time semantics (in Temporal, PlainDateTime.compare()) the date implicitly converts to midnight on that day, so it comes before both of the date-times. If we use date semantics (PlainDate.compare()), 2022-06-01 and 2022-06-01 12:00:00 are equal as we determined in Question 1, so I wouldn’t say it’s “between” the two date-times.
(Why these numbers?6 The compare methods return −1, 0, or 1, according to the convention used by Array.prototype.sort, so that you can do things like arr.sort(Temporal.PlainDate.compare). 0 means the arguments are equal and −1 means the first comes before the second.)
But maybe the answer still depends a little bit on what your definition of “between” is. If it means the date-times form a closed interval instead of an open interval, and we are using date semantics, then the answer is yes.7
Question 3
Is the time 2022-06-01 12:00:00 after the date 2022-06-01?
After thinking about the previous two questions, this should be clear. If we’re using date semantics, the two are equal, so no. If we’re using date-time semantics, and we choose to convert a date to a date-time by assuming midnight as the time, then yes.
Other people’s answers
I saw a lot of answers saying that you need more context to be able to compare the two, so I estimate that the way Temporal requires that you give that context, instead of assuming one or the other, does fit with the way that many people think. However, that wasn’t the only kind of reply I saw. (Otherwise the discussion wouldn’t have been that interesting!) I’ll discuss some of the other common replies that I saw in the Twitter thread.
“Yes, no, no: truncate to just the dates and compare those, since that’s the data you have in common.” People who said this seem like they might naturally gravitate towards date semantics. I’d estimate that date semantics are probably correct for more use cases. But maybe not your use case!
“No, no, yes: a date with no time means midnight is implicit.” People who said this seem like they might naturally gravitate towards date-time semantics. It makes sense to me that programmers think this way; if you’re missing a piece of data, just fill in 0 and keep going. I’d estimate that this isn’t how a lot of nontechnical users think of dates, though.
In this whole post I’ve assumed we assume the time is midnight when we convert a date to a date-time, but in the messy world of dates and times, it can make sense to assume other times than midnight, as well. This comes up especially if time zones are involved. For example, you might assume noon, or start-of-day, instead. Start-of-day is often, but not always midnight:
“These need to have time zones attached for the question to make sense.” If this is your first reaction when you see a question like this, great! If you write JavaScript code, you probably make fewer bugs just by being aware that JavaScript’s Date object makes it really easy to confuse time zones.
I estimate that Temporal’s ZonedDateTime type is going to fit more use cases in practice than either PlainDate or PlainDateTime. In that sense, if you find yourself with this data and these questions in your code, it makes perfect sense to ask yourself whether you should be using a time-zone-aware type instead. But, I think I’ve given some evidence above that sometimes the answer to that is no: for example, the pedometer data that I mentioned above.
“Dates without times are 24-hour intervals.” Also mentioned as “all-day events”. I can sort of see where this comes from, but I’m not sure I agree with it. In the world where JavaScript Date is the only tool you have, it probably makes sense to think of a date as an interval. But I’d estimate that a lot of non-programmers don’t think of dates this way: instead, it’s a square on your calendar!
It’s also worth noting that in some calendar software, you can create an all-day event that lasts from 00:00 until 00:00 the following day, and you can also create an event for just the calendar date, and these are separate things.
A 24-hour interval and a calendar date. Although notably, Google Calendar collapses the 24-hour event into a calendar-date event if you do this.
“Doesn’t matter, just pick one convention and stick with it.” I hope after reading this post you’re convinced that it does matter, depending on your use case.
“Ugh!” That’s how I feel too and why I wrote a whole blog post about it!
How do I feel about the choices we made in Temporal?
I’m happy with how Temporal encourages the programmer to handle these cases. When I went to try out the comparisons that were suggested in the original tweet, I found it was natural to pick either PlainDate or PlainDateTime to represent the data.
One thing that Temporal could have done instead (and in fact, we went back and forth on this a few times before the proposal reached its currently frozen stage in the JS standardization process) would be to make the choice of data type, and therefore of comparison semantics, more explicit.
For example, one might make a case that it’s potentially confusing that the 12:00:00 part of the string in Temporal.PlainDate.from('2022-06-01').equals('2022-06-01 12:00:00') is ignored when the string is converted to a PlainDate. We could have chosen, for example, to throw if the argument to PlainDate.prototype.equals() was a string with a time in it, or if it was a PlainDateTime. That would make the code for answering question 1 look like this:
This approach seems like it’s better at forcing the programmer to make a choice consciously by throwing exceptions when there is any doubt, but at the cost of writing such long-winded code that I find it difficult to follow. In the end, I prefer the more balanced approach we took.
Conclusion
This was a really interesting problem to dig into. I always find it good to be reminded that no matter what I think is correct about date-time handling, someone else is going to have a different opinion, and they won’t necessarily be wrong.
I said in the beginning of the post: “to get a good answer, you need to specify which concept you are talking about.” Something we’ve tried hard to achieve in Temporal is to make it easy and natural, but not too obtrusive, to specify this. When I went to answer the questions using Temporal code, I found it pretty straightforward, and I think that validates some of the design choices we made in Temporal.
I’d like to acknowledge my employer Igalia for letting me spend work time writing this post, as well as Bloomberg for sponsoring Igalia’s work on Temporal. Many thanks to my colleagues Tim Chevalier, Jesse Alama, and Sarah Groff Hennigh-Palermo for giving feedback on a draft of this post.
[1] 777 days at the time of writing, according to Temporal.PlainDate.from('2020-01-13').until(Temporal.Now.plainDateISO())
[2] A common source of bugs with JavaScript’s legacy Date when the made-up time of day doesn’t exist due to DST
[3] “Semantics” is, unfortunately, a word I’m going to use a lot in this post
[4] “Time” in Temporal refers to a time on a clock face, with no date associated with it
[6] We don’t have methods like isBefore()/isAfter() in Temporal, but this is a place where they’d be useful. These methods seem like good contenders for a follow-up proposal in the future
To some degree, the stuff below is one of those “I’m writing this down somewhere so I don’t forget it myself” topics, of which I have [checks notes…] about fifteen draft posts currently gathering electron dust. But it’s also potentially of interest to one or two other people, so here we are.
For background, if you’ve been lucky enough to not hear about it before, I’m currently in a postgraduate research-degree program in typography. A lot of my research work day-to-day involves consuming & tracking info from printed documents. Despite what Silicon Valley’s OLED-Industrial Complex tells you, printed matter is not a low-quality substitute for digital ideals; it’s its own thing, and it comes with it own challenges when you use it as data.
And that’s a constant source of headaches. So I’m going to jot down some of the process and the challenges / open questions that I run across regularly in my research days; if I do that I might have to reinvent those wheels less often, and there’s always the chance that some other goofball out there will see it and find something helpful.
Le grand scheme
So here’s the rough picture. Ideally, I’d like to have all the source material that I collect accessible in the same place, so when the occasion arises I could sift through it in a couple of different fashions:
Full-text searches — e.g., grabbing all the material that uses the term “sector kerning”, for some comparative reason
Topical tagging — letting me attach my own labels to things, even if the label isn’t a word that’s found in the source doc, such as “disputed” or “real-time”
Tracking usage — I ought to know if I’m actually using a quote from something in some written material. Technically that could be a tag, but it’s a little more involved.
For digital sources, this isn’t too terrible. Digital-original documents are pretty searchable from desktop or CLI tools (although you need a good directory structure). You definitely need to actually grab downloaded page-snapshots of web sites, though: people rearrange their personal and institutional pages ALL THE TIME; they bork up the URI structure and don’t bother to fix it, they change their domain name, etc.
You also have to actually fork (not star…) GitHub repositories and download them, cause people take down that stuff, too. And you cannot rely on the Internet Archive to Wayback-machine everything. It doesn’t always work, and the crawls stop at a finite depth. Pretty famously in the type world, the Typedrawers web forum got taken offline a few years ago, erasing literally decades of industry discussion. The site owners never got around to restoring it. But even before that, they halfheartedly converted a bunch of the threads to some new CMS, which broke (a) every Wayback Machine link and (b) broke every internal URL in every thread and (c) broke every “previous page | next page” link in every Wayback link that did exist. They still have not been brought to justice.
Anyway, I digress. That minor effort works fine for digital originals. It gets a lot harder for printed sources. This is where a real database-driven tool becomes mandatory. I’ve been using Zotero, which is fine as it goes although it has plenty of pain points. It is, at least, something that you can run entirely on your own machine (although they do try to rope you into using their hosted service, which you have to pay for if you go over the comically-small limit). And, obviously, it’s FOSS and runs on Linux machines.
The gist is, however, that you import every item into the Zotero library, and it handles all the metadata-level stuff at the top level. For each item you can store any number of files or notes. Great for having a source PDF, a translation, a set of notes, and an alternate version of the source you find months later with slightly different wording. Hooray.
A couple of things become tricky about getting the paper original into Zoteroized form. Here’s how I break it down:
If I have a scanned version of an article or other published document, it needs to be OCRed before the text is available for Method 1 (full-text search). Super hard.
If I have a LONG FORM physical book, then I can’t scan the whole thing and probably wouldn’t want to. In fact, it might not even be possible to, if it can’t be layed out flat.
If I have an un-published source, such as some personal archive material or correspondence, then I have to wrangle all the problems of the first bullet point but also manually do all of the metadata-like stuff, because Zotero cannot handle it at all. And it usually has to be photographed or manually transcribed like the stuff in the second bullet point.
Seems easy enough.
But there’s another dimension to look at.
The Secondth Dimension
That bullet point above really just looks at the presence of the item: do I have a scan? / do I have the physical item only? / do I not have the item at all, and have to make do with temporary access to it?
The other thing I’ve found is that you have to develop distinctly different workflows based on the potential uses of them item, after it gets into the digital system:
Things that you need to quote. This needs to be accurate. If it’s a digital original, great. If it’s a good scan, also reasonably doable. If it’s unscannable, that’s tricky: e.g., I need to just capture (accurately) the passage that I would / could quote, and link that as a “note” into the Zotero metadata-record for the item. That’s hitting #1 and #3 on the above numbered list in particular. Ideally I could photograph a passage and have that OCRed, rather than me re-typing it by hand.
Things you need to reproduce an image from.
Things you need to get an image from, but which you cannot reproduce the image. Generally that’s a licensing issue. People want compensation for almost any image that gets reprinted; for quoting a document there is a really high threshold to reach before that becomes a concern.
So that’s kind of a 3×3 matrix. And I keep saying “scan” in the generic sense, but that also doesn’t quite capture all the possible issues. For example, you could download/receive-from-a-third-party a digital original does not have text embedded, possibly making it essentially a PDF with just a TIFF image of the page in the middle. And anything that you photograph or scan yourself can have all kinds of image corrections needed, such as skew or 3D warp (for the latter, consider the curvature of a book page when you’re holding down by the spine over a scanner). Those things can affect whether or not OCR is even possible. Actually, that can happen with material you get from elsewhere, too….
Then there’s all the problems of OCR itself: error rate, whether or not you can edit and correct errors, and so on. Plus whether or not you can OCR complex layouts, in more than one language. Luckily I’ve only had to deal with English + German + French so far, but it’s not nothing.
Finally, you get to the big weirdnesses that come with doing all this document processing for typography material. For example, typography articles often have lots of illustrations … of text. As is letters. And words. Even whole lines and paragraphs. Which need to be preserved as images, not converted to OCR. Or maybe you do also want them to be OCR; you might remember that an illustration was of the word “NAVVIES” and want to search for that.
Those are the pieces. You get varying workflows out of each of those combos, multiplied (possibly) by some of those later quirks. Anyway, more on that to come in the next post; like I said above this is mostly me jotting down things to record the workflows, but I’m trying to slice it into thinner chunks because otherwise I never finish writing the posts.
If you’re curious about any of the details, they’ll be in a follow-up. FORTUNATELY, if you’re a normal person and not, therefore, interested in the details, then at least now you know what I’m titling this little series of posts — so you can skip the next one with a maximum of comfort and ease.
After a few months of slow but steady progress, a new release of Portfolio is out . This new release comes with the ability to fully manage external devices, better feedback and responsiveness when copying big files to slow devices and many bugs fixes.
By popular demand, the main addition to Portfolio is the ability to fully manage external devices, this means; detecting external devices, unlocking encrypted devices, mounting and ejecting. For this release, I focused on getting the udisks2 integration right, but there’s still room for improvement on the UX department. A shout out to @ahoneybun for testing my two previous (and unsuccessful ) attempts to implement this.
Another noticeable improvement is that now copying operations display progress feedback on individual files. Previously, there wasn’t any, which led to the impression of “no feedback at all” when copying big files.
A related improvement is that copying operations now do a better job displaying the real progress, specially when copying files to slow external devices. No more suspiciously fast copying operations, which later turn into several minutes of undetermined wait time when ejecting these devices.
On the bug fixing department, hidden Trash folders are no longer created on external devices until they’re really needed, send to Trash button won’t show on devices with no Trash folder, Portfolio no longer crashes on the Sway tiling compositor, broken symlinks are now handled properly and the same file size unit is used consistently through all the application.
Moving forward, for the short term, I want to improve the external devices management UX and give these beautiful GNOME 42 folder icons a try . For the long term, I would love to port this application to GTK4 and Libadwaita.
A recent trend in open source projects seems to be to avoid releasing proper release archives (whether signed with GPG or not). Instead people add Git tags for release commits and call it a day.
A long and arduous debate could be had whether this is "wrong", "right" and whether Git hashes are equivalent to proper tarballs or not, or if --depth=1 is a good thing or not. We're not going to get into that at all.
Instead I'd like to kindly ask that all projects that do releases of any kind to provide actual release tarballs for the following two reasons:
It takes very little effort on your part.
Proper release archives make things easier for many people consuming your project.
This makes sense just from a pure numbers game perspective: a little work on your part saves a lot of work for many other people. So please do it.
What about Github automatic archive generation?
Github does provide links to download any project commit (and thus release) as an archive. This is basically a good thing but it has two major issues.
The filenames are of type v1.0.0.tar.gz. So from a file name you can't tell what it contains and further if you have two dependencies with the same version number, the archive files will have the same name and thus clash. Murphy's law says that this is inevitable.
The archives that Github generates are not stable. Thus if you redownload them the files may have different checksums. This is bad because doing supply chain verification by comparing hashes will give you random failures.
The latter might get fixed if Github changes their policy to guaranteed reproducible downloads. The former problem still exists.
A simple webui-only way to do it
If you don't want to use git archive to generate your releases for whatever reason, there is a straightforward way of doing the release using only the web ui.
Create your release by tagging as usual.
Download the Github autogenerated tarball with a browser (it does not matter whether you choose zip or tar as the format, either one is fine).
Rename the v1.0.0.tar.gz file to something like myproject-1.0.0.tar.gz.
Go to the project tags page, click on "create a new release from tag".
In the code review cycles for some of the PWA project PRs I’ve put out, the question has been raised about the proper way to version D-Bus APIs, since I am adding a new D-Bus API to GNOME Web. I learned a couple things and thought I’d share in case it’s useful.
As D-Bus APIs evolve over time and new functionality is added or existing functionality is removed, in most cases you don’t have the luxury of ensuring that all clients are updated in lockstep, so it’s important to think about how existing clients can continue to work without modification, and how clients which are aware of the new functionality can take advantage of it. So there are two types of compatibility to worry about:
Backwards compatible changes to the API, which are changes that do not cause existing client code to break. For example, if a method accepts a dictionary of options, each a string key mapped to a value, adding a new supported option key does not cause existing clients to stop working; they just won’t be able to take advantage of the new option. That’s assuming the behavior of the D-Bus service with the new option omitted is the same as it was before the new option was added.
Backwards incompatible changes to the API, which are changes that would cause existing client code to break if it’s not updated. For example, changing the name of a method, changing the parameters of a method, or removing a method.
The de facto way to handle backwards compatible API changes, at least in xdg-desktop-portal as well as org.gnome.Mutter.ScreenCast, is to increment an integer Version property when such changes are made (in the portal code the property is not capitalized but the spec recommends capitalization). This allows clients to check at runtime what functionality is available, and only make use of new functionality when the running service has it. This is especially useful for Flatpaks since a Flatpak app needs to be able to run regardless of the version of xdg-desktop-portal or its backends installed on the host; a major benefit of Flatpaks is that they don’t have version requirements for software installed on the host system. This scheme seems to work pretty well for the portal code and its many clients. Here’s an example of how to check the available version of a portal interface in C code.
Per the D-Bus API Design Guidelines, the way to handle backwards incompatible API changes is to leave the existing interface as it is, continue to support it as before, and make a new interface with an incremented number on the end like com.example.MyService2 and use that in the service name, interface name, and object path. While the spec says to add a 1 to the end of the original service name, in practice that is often left off since com.example.MyService2 can just as well follow com.example.MyService as com.example.MyService1. An example of this is the interface org.gnome.ShellSearchProvider2 provided by gnome-shell.
Earlier this week, Neil McGovern announced that he is due to be stepping down as the Executive Director as the GNOME Foundation later this year. As the President of the board and Neil’s effective manager together with the Executive Committee, I wanted to take a moment to reflect on his achievements in the past 5 years and explain a little about what the next steps would be.
Since joining in 2017, Neil has overseen a productive period of growth and maturity for the Foundation, increasing our influence both within the GNOME project and the wider Free and Open Source Software community. Here’s a few highlights of what he’s achieved together with the Foundation team and the community:
Improved public perception of GNOME as a desktop and GTK as a development platform, helping to align interests between key contributors and wider ecosystem stakeholders and establishing an ongoing collaboration with KDE around the Linux App Summit.
Worked with the board to improve the maturity of the board itself and allow it to work at a more strategic level, instigating staggered two-year terms for directors providing much-needed stability, and established the Executive and Finance committees to handle specific topics and the Governance committees to take a longer-term look at the board’s composition and capabilities.
Arranged 3 major grants to the Foundation totaling $2M and raised a further $250k through targeted fundraising initiatives.
Grown the Foundation team to its largest ever size, investing in staff development, and established ongoing direct contributions to GNOME, GTK and Flathub by Foundation staff and contractors.
Launched and incubated Flathub as an inclusive and sustainable ecosystem for Linux app developers to engage directly with their users, and delivered the Community Engagement Challenge to invest in the sustainability of our contributor base – the Foundation’s largest and most substantial programs outside of GNOME itself since Outreachy.
Achieved a fantastic resolution for GNOME and the wider community, by negotiating a settlement which protects FOSS developers from patent enforcement by the Rothschild group of non-practicing entities.
Stood for a diverse and inclusive Foundation, implementing a code of conduct for GNOME events and online spaces, establishing our first code of conduct committee and updating the bylaws to be gender-neutral.
Established the GNOME Circle program together with the board, broadening the membership base of the foundation by welcoming app and library developers from the wider ecosystem.
Recognizing and appreciating the amazing progress that GNOME has made with Neil’s support, the search for a new Executive Director provides the opportunity for the Foundation board to set the agenda and next high-level goals we’d like to achieve together with our new Executive Director.
In terms of the desktop, applications, technology, design and development processes, whilst there are always improvements to be made, the board’s general feeling is that thanks to the work of our amazing community of contributors, GNOME is doing very well in terms of what we produce and publish. Recent desktop releases have looked great, highly polished and well-received, and the application ecosystem is growing and improving through new developers and applications bringing great energy at the moment. From here, our largest opportunity in terms of growing the community and our user base is being able to articulate the benefits of what we’ve produced to a wider public audience, and deliver impact which allows us to secure and grow new and sustainable sources of funding.
For individuals, we are able to offer an exceedingly high quality desktop experience and a broad range of powerful applications which are affordable to all, backed by a nonprofit which can be trusted to look after your data, digital security and your best interests as an individual. From the perspective of being a public charity in the US, we also have the opportunity to establish programs that draw upon our community, technology and products to deliver impact such as developing employable skills, incubating new Open Source contributors, learning to program and more.
For our next Executive Director, we will be looking for an individual with existing experience in that nonprofit landscape, ideally with prior experience establishing and raising funds for programs that deliver impact through technology, and appreciation for the values that bring people to Free, Open Source and other Open Culture organizations. Working closely with the existing members, contributors, volunteers and whole GNOME community, and managing our relationships with the Advisory Board and other key partners, we hope to find a candidate that can build public awareness and help people learn about, use and benefit from what GNOME has built over the past two decades.
Neil has agreed to stay in his position for a 6 month transition period, during which he will support the board in our search for a new Executive Director and support a smooth hand-over. Over the coming weeks we will publish the job description for the new ED, and establish a search committee who will be responsible for sourcing and interviewing candidates to make a recommendation to the board for Neil’s successor – a hard act to follow!
I’m confident the community will join me and the board in personally thanking Neil for his 5 years of dedicated service in support of GNOME and the Foundation. Should you have any queries regarding the process, or offers of assistance in the coming hiring process, please don’t hesitate to join the discussion or reach out directly to the board.
January 2022 was the sunniest January i’ve ever experienced. So I spent its precious weekends mostly climbing around in the outside world, and the weekdays preparing for the enourmous Python 3 migration that one of Codethink’s clients is embarking on.
Since I discovered Listenbrainz, I always wanted to integrate it with Calliope, with two main goals. The first, to use an open platform to share and store listen history rather than the proprietary Last.fm. And the second, to have an open, neutral place to share playlists rather than pushing them to a private platform like Spotify or Youtube. Over the last couple of months I found time to start that work, and you can now sync listen history and playlists with two new cpe listenbrainz-history and cpe listenbrainz commands. So far playlists can only be exported *from* Listenbrainz, and the necessary changes to the pylistenbrainz binding are still in review, but its a nice start.
The GNOME Foundation recognizes that mentoring is a time consuming effort, and for this reason, we will be giving accepted mentors an option to receive the $500 USD stipend that Google pays the organization for each contributor. Mentors can choose to revert the fund into a donation to the GNOME Foundation. Some payment restrictions may apply (please contact us for questions).
Proposals will be reviewed by the GNOME GSoC Admins and posted in our Project Ideas page.
If you have any doubts, please don’t hesitate to contact the GNOME GSoC Admins on this very same forum or on Matrix in the channel #soc:gnome.org
After roughly 20 years and counting up to 0.40 in release numbers, I've decided to call the next version of the xf86-input-wacom driver the 1.0 release. [1] This cycle has seen a bulk of development (>180 patches) which is roughly as much as the last 12 releases together. None of these patches actually added user-visible features, so let's talk about technical dept and what turned out to be an interesting way of reducing it.
The wacom driver's git history goes back to 2002 and the current batch of maintainers (Ping, Jason and I) have all been working on it for one to two decades. It used to be a Wacom-only driver but with the improvements made to the kernel over the years the driver should work with most tablets that have a kernel driver, albeit some of the more quirky niche features will be more limited (but your non-Wacom devices probably don't have those features anyway).
The one constant was always: the driver was extremely difficult to test, something common to all X input drivers. Development is a cycle of restarting the X server a billion times, testing is mostly plugging hardware in and moving things around in the hope that you can spot the bugs. On a driver that doesn't move much, this isn't necessarily a problem. Until a bug comes along, that requires some core rework of the event handling - in the kernel, libinput and, yes, the wacom driver.
After years of libinput development, I wasn't really in the mood for the whole "plug every tablet in and test it, for every commit". In a rather caffeine-driven development cycle [2], the driver was separated into two logical entities: the core driver and the "frontend". The default frontend is the X11 one which is now a relatively thin layer around the core driver parts, primarily to translate events into the X Server's API. So, not unlike libinput + xf86-input-libinput in terms of architecture. In ascii-art:
| +--------------------+ | big giant /dev/input/event0->| core driver | x11 |->| X server +--------------------+ | process |
+-----------------------+ | /dev/input/event0->| core driver | gwacom |--| tools or test suites +-----------------------+ |
This isn't a public library or API and it's very much focused on the needs of the X driver so there are some peculiarities in there. What it allows us though is a new wacom-record tool that can hook onto event nodes and print the events as they come out of the driver. So instead of having to restart X and move and click things, you get this:
This is YAML which means we can process the output for comparison or just to search for things.
A tool to quickly analyse data makes for faster development iterations but it's still a far cry from reliable regression testing (and writing a test suite is a daunting task at best). But one nice thing about GObject is that it's accessible from other languages, including Python. So our test suite can be in Python, using pytest and all its capabilities, plus all the advantages Python has over C. Most of driver testing comes down to: create a uinput device, set up the driver with some options, push events through that device and verify they come out of the driver in the right sequence and format. I don't need C for that. So there's pull request sitting out there doing exactly that - adding a pytest test suite for a 20-year old X driver written in C. That this is a) possible and b) a lot less work than expected got me quite unreasonably excited. If you do have to maintain an old C library, maybe consider whether's possible doing the same because there's nothing like the warm fuzzy feeling a green tick on a CI pipeline gives you.
[1] As scholars of version numbers know, they make as much sense as your stereotypical uncle's facebook opinion, so why not. [2] The Colombian GDP probably went up a bit
Since the start of the year I’ve been doing weeklybeats. So far it’s been possible mainly thanks to the Dirtywave M8’s ability to be picked up, instantly turned on and creating. I have to admit to mostly composing in bed (and only occasionally waking up my better half by shaking to the beat).
I’m not going to be spamming the planet with every track, but I do want to share some that I feel worked out. This one is a jam done on the Digitakt (that I actually modified to run on a li-ion battery) and the M8 doing most of the heavy lifting. The track started by setting up Fugue Machine like sequence in the M8. A friend of mine suggested to spice the ambient with a bit of a beat, which I used a Digitakt for. I now map the mixer on the M8 onto the 8 encoders of the Digitakt, but for the jam I was still using the internal keypad.
I really enjoy stepping back into my tracking shoes after two decades, especially when I ran into the old Buzz crew on the Dirtywave Discord server. Shout out to Ilya and Noggin’ who’ve made my re-entry to music super enjoyable.
Flathub joins OBS Studio’s Ubuntu PPA in the list of official builds.
On Ubuntu, both can be installed and used without any major annoyance, since Flatpak can easily be installed there – though it would be great if Flatpak was distributed by default on Ubuntu, but oh well, such is life. For other Linux distributions, especially the ones not based on Debian, the Flathub package is probably the easiest one to install, and certainly the most complete.
Official Build
Becoming an official build is not only a badge, or a community recommendation, in OBS Studio’s case. It brings features only enabled in official builds.
The first and most obvious one is services integration. OBS Studio builds its Flatpak package on its own CI, and enables this feature using private keys that aren’t otherwise available to distribution packages. This build is then published on Flathub directly. ¹
Another benefit is that the OBS Studio community can effectively enable and support a lot more Linux users to use it the way the community envisioned. People on Fedora, Arch, Gentoo, Endless OS, Debian, elementary OS, and dozens of other distros can use a complete, featureful, and supported build of OBS Studio. In many cases, these distros come with Flatpak and even Flathub by default, and OBS Studio can be installed with a simple search in their app centers. It couldn’t possibly be easier than that.
Wild Packaging
In addition to enabling services integration, Flatpak makes it much easier for OBS Studio to package its complicated dependencies. For example, OBS Studio needs to patch CEF internally for it to be used as the browser source, and browser docks, and this makes it pretty difficult to package it using traditional packages, since it could conflict with the upstream CEF package. FFmpeg is another case of a patched dependency.
Unfortunately, many distro packages don’t ship with browser integration, and don’t use the patched FFmpeg. Perhaps even worse, some unofficial packages add many third-party unofficial plugins by default. This vast array of packaging formats enabling different features, and shipping different plugins, make it much harder for the support volunteers to support Linux users properly.
Speaking for myself, even when people were using the Flathub package before it was made official, the fact that it was a Flatpak made it significantly easier to track down bugs. And, interestingly, it made it much easier to track down bug in other packages, such as distros mispackaging or not installing all portal dependencies correctly. In some sense, Flatpak may have helped distributions package dependencies better!
Plugin Support
Plugins are the heart and soul of OBS Studio. People use a variety of third-party plugins, and supporting them is important for a complete experience.
Flatpak has support for extensions, which are used to audio plugins for example. OBS Studio is able to detect plugins installed via Flatpak. ²
It is easy to install OBS Studio plugins distributed through Flathub using GNOME Software
The number of OBS Studio plugins available on Flathub is numerically small, but their packaging is robust and they’re well supported. I’m confident in these plugins – many of which are maintained by their own authors! – and I’m hopeful that we’ll see more of them showing up there in the future.
If you are a plugin author that wants your plugin to show up on app stores like the screenshot above, I’ve written some documentation on the process. It should be relatively easy to do that, but if you have any questions about it, please let me know. I’d like to make this as well documented and simple as possible, so that we can focus less on technicalities, and more on the quality of the packaging and metadata. The Flatpak community is also welcoming and willing to help everyone, so feel free to join their Matrix room.
Conclusion
It is super exciting to me that OBS Studio is being published on Flathub officially. I think it makes it so much more convenient to install on Linux! I’m also looking forward the recent work on introducing payments and official badges on Flathub, and will make sure that OBS Studio gains such badge as soon as it’s available.
Other than these Flatpak-related news, there are more PipeWire changed in the pipeline for future OBS Studio releases, and some of these changes can be really exciting too! Stay tuned as we progress on the PipeWire front, I’m sure it will enable so many interesting features.
As I write this article, I’m starting to feel like the dream of an actual Linux platform is slowly materializing, right here, in front of us. OBS Studio is spearheading this front, and helping us find what the platform is still missing for wider adoption, but the platform is real now. It’s tangible, apps can target it.
I’d like to thank all the contributors that made this possible, and in particular, tytan652 and columbarius. Nothing I wrote about here would have been possible without your contributions. I’d like to also thank Flathub admins for helping figuring out the publish pipeline. Finally, I’d like to thank the OBS Studio community for accepting these contributions, and for all the patience while we figured things out.
¹ – Massive thanks to tytan652 for implementing secret keys support in flatpak-builder
² – If a plugin is not available on Flathub, you can still manually install them. This is dangerous though, and can make OBS Studio crash. If you want to see a plugin on Flathub, it is always best to politely suggest that for the author!
In 2017, I was attending FOSDEM when GNOME announced that I was to become the new Executive Director of the Foundation. Now, nearly 5 years later, I’ve decided the timing is right for me to step back and for GNOME to start looking for its next leader. I’ve been working closely with Rob and the rest of the board to ensure that there’s an extended and smooth transition, and that GNOME can continue to go from strength to strength.
GNOME has changed a lot in the last 5 years, and a lot has happened in that time. As a Foundation, we’ve gone from a small team of 3, to employing people to work on marketing, investment in technical frameworks, conference organisation and much more beyond. We’ve become the default desktop on all major Linux distributions. We’ve launched Flathub to help connect application developers directly to their users. We’ve dealt with patent suits, trademarks, and bylaw changes. We’ve moved our entire development platform to GitLab. We released 10 new GNOME releases, GTK 4 and GNOME 40. We’ve reset our relationships with external community partners and forged our way towards that future we all dream of – where everyone is empowered by technology they can trust.
For that future, we now need to build on that work. We need to look beyond the traditional role that desktop Linux has held – and this is something that GNOME has always been able to do. I’ve shown that the Foundation can be more than just a bank account for the project, and I believe that this is vital in our efforts to build a diverse and sustainable free software personal computing ecosystem. For this, we need to establish programs that align not only with the unique community and technology of the project, but also deliver those benefits to the wider world and drive real impact.
5 years has been the longest that the Foundation has had an ED for, and certainly the longest that I’ve held a single post for. I remember my first GUADEC as ED. As you may know, like many of you, I’m used to giving talks at conferences – and yet I have never been so nervous as when I walked out on that stage. However, the welcome and genuine warmth that I received that day, and the continued support throughout the last 5 years makes me proud of what a welcoming and amazing community GNOME is. Thank you all.
Since the early days of working on the macOS backend for GTK 4 I knew eventually we’d have to follow suit with what the major browsers were doing in terms of drawing efficiency. Using OpenGL was (while deprecated, certainly not going anywhere) fine from a performance standpoint of rendering. But it did have a few drawbacks.
In particular, OpenGL (and Metal afaik) layers don’t have ways to damage specific regions of the GPU rendering. That means as we’d flip between front and back buffers, the compositor will re-composite the whole window. That’s rather expensive for areas that didn’t change, even when using a “scissor rect”.
If you’re willing to go through the effort of using IOSurface, there does exist another possibility. So this past week I read up on the APIs for CALayer and IOSurface and began strapping things together. As a life-long Linux user, I must say I’m not very impressed with the macOS experience as a user or application author, but hey, it’s a thing, and I guess it matters.
The IOSurface is like a CPU-fronted cache on a GPU texture. You can move the buffer between CPU and GPU (which is helpful for software rendering with cairo) or leave it pretty much just in the GPU (unless it gets paged out). It also has a nice property that you can bind it to an OpenGL texture using GL_TEXTURE_RECTANGLE. Once you have a texture, you can back GL_FRAMEBUFFER with it for your rendering.
That alone isn’t quite enough, you also need to be able to attach that content to a layer in your NSWindow. We have a base layer which hosts a bunch of tiles (each their own layer) whose layer.contents property can be mapped directly to an IOSurfaceRef, easy peasy.
With that in place, all of the transparent regions use tiles limited to the transparent areas only (which will incur alpha blending by the compositor). The rest of the area is broken up into tiles which are opaque and therefore do not require blending by the compositor and can be updated independently without damaging the rest of the window contents.
You can see the opaque regions by using “Quartz Debug” and turning on the “Show opaque regions” checkbox. Sadly, screen-capture doesn’t appear to grab the yellow highlights you get when you turn on the “Flash screen updates” checkbox, so you’ll have to imagine that.
Opaque regions displayed in green
This is what all the major browsers are doing on macOS, and now we are too.
This also managed to simplify a lot of code in the macOS backend, which is always appreciated.
Probably only a fraction of you had a chance to see Droneman in a theatre. It’s available on Netflix, so perhaps not universally, but ever so slightly more available to a global audience. Why would I be plugging a movie? Because it’s my only entry in IMDB and features a spectacular performance by my son, that’s why!
None of this is in upstream Godot yet. It is only a proposal. The actual code can be obtained from the meson2 branch of this repository. Further discussion on the issue should be posted here.
The problem
Godot's code base is split into independent modules that can be enabled and disabled at will. However many games require custom native code and thus need to define their own modules. The simplest way to do this (which, I'm told, game developers quite often do) is to fork the upstream repo and put your your code in it. This works and is a good solution for one-off projects that write all extra code by themselves. This approach also has its downsides. The two major ones are that updating to a newer version of the engine can turn into a rebasing hell and that it is difficult to combine multiple third party modules.
Ideally what you'd want to do is to take upstream Godot and then take a third party module for, say, physics and a second module written by completely different people that does sound effects processing, combine all three and have things just work. Typically those modules are developed in their own repositories. Thus we'd end up with the following kind of a dependency graph.
This would indicate a circular dependency between the two repositories: in order to build the external module you need to depend on the Godot repo and in order to build the Godot you need to depend on the external repository. This is bad. If there's one thing you don't want in your source code it is circular dependencies.
Solving it using Meson's primitives
If you look at the picture in more detail you can tell that there is no circular dependencies between individual targets. Thus to solve the problem you need some way to tell the external dependency how to get the core libraries and headers it needs and conversely a way for the main build to extract from the external project what modules it has built and where they are. As Meson subprojects are built in isolation one can't just blindly poke the innards of other projects as one can do if everything is in a single megaproject.
The way Godot's current build is set up is that first it defines the core libraries, then all the modules and finally things on top of that (like the editor and main executable). We need to extend this so that external modules are set up at the same time as internal modules and then joined into one. Thus the final link won't even be able to tell the difference between external and internal modules.
First we need to set up the dependency info for the core libraries, which is done like this:
First we set up a dependency object that encapsulates everything needed to build extension modules and then specify that whenever a dependency called godotcore is looked up, Meson will return the newly defined object. This even works inside subprojects that are otherwise isolated from the master project.
Assuming we have a list of external module subprojects available, we can go through them one by one and build them.
The first line runs the subproject, the latter two are ignored for now, we'll come back to them. The subproject's meson.build file starts by getting the dependency info.
godotcore_dep = dependency('godotcore')
Then it does whatever it needs to build the extension module. Finally it defines the information that the main Godot application needs to use the module:
In this case I have converted Godot's internal tga module to build as an external module hence the name. This concludes the subproject and execution resumes in the master project and the two remaining lines grab the module build information and name and append them to the list of modules to use.
This is basically it. There are obviously more details needed like integrating with Godot's documentation system for modules but the basic principle for those is the same. With this approach the integration of multiple external modules is simple: you need to place them in the main project's subprojects directory and add their names to the list of external module subprojects. All of this can be done with no code changes to the main Godot repo so updating it to the newest upstream version is just a matter of doing a git pull.
I’m Victoria Martinez de la Cruz, but you can call me Vicky. First time I heard about the open source concept I was pretty young, I’d say, 12 years old. At that time it was quite common to use IRC to chat with friends and to get to know people. And it was precisely inContinue reading "An Open Source Journey that began at 12"
Mistakes were made¹, and after recent maintenance,
Jordan asked Infrastructure Team if there is a chance GNOME Nightly
(and its younger sibling GNOME OS) could be moved somewhere with faster network
and more storage. After short discussion, we decided to move it to AWS (thanks
to promotional credits for open source projects). The new server has three
times more space, uses SSD instead of HDD, and should offer up to 10 Gbps of
network bandwidth.
It quickly became apparent we underestimated GNOME Nightly popularity by a
large margin. On the second day, the new server transmitted almost 500 GB of
data. As we wanted to limit potential egress costs, we reached out to
CDN77, and they quickly agreed to help us. CDN77 team
aren’t stranger to the open source world, helping other projects like KDE,
Gentoo and Manjaro.
With the new server fully dedicated to GNOME Nightly, and turbo fast CDN in
front, I can easily saturate my 1Gbit connection at home while downloading the
infamous org.gnome.Sdk.Debug//master. Since the switch on January 22nd, CDN77
has served for us over 40 million requests, which sums up to 11 TB of traffic.
While it is well-known nobody notices infrastructure until it’s broken, here’s
hoping it just became more invisible.
Thanks to AWS and CDN77 for making it possible!
¹ Slow IO caused by spinning disks aside, the implementation of
repository pruning in Flatpak before the 1.11.1 release was prone to remove
actually required ostree objects if a new build was being published at the same
time.
It was a bit quiet around Fragments, many had the fear that Fragments will no longer be maintained.
These rumors I can proudly counter, and can now announce that Fragments 2.0 is now available after about a year of development!
Technical difficulties
Until recently Fragments was written in Vala, and used libtransmission as a backend. This had some disadvantages, e.g. a vapi file has to be maintained (the glue between the Transmission C API, and the Fragments Vala code).
In addition to that there are considerations from the Transmission maintainers to replace the C API with C++. This would mean that Fragments would not be able to use the Transmission API without creating (and maintaining) another wrapper (C++ -> C). In the long run I didn’t think this was very realistic.
And to be honest, Fragments was my last Vala application, and I was thinking for a long time how I could replace it with Rust
The new beginning
The first thing I needed was a suitable BitTorrent backend. Since I have neither the knowledge nor the time to write my own BitTorrent implementation in the long run, my only option was to fall back on something already existing. Unfortunately, there is currently no BitTorrent implementation written in Rust that is comparable to libtransmission in terms of stability and features.
After a few brainstorming sessions I came up with the idea to continue using Transmission, but not via the C API, but to use transmission-daemon, and then communicate via its HTTP RPC API. This has several advantages:
Clean abstraction between the BitTorrent backend, and the actual application (this has some nice side effects, more on that later!)
Already existing functions in Fragments 1 can be ported directly
The later migration from Vala to Rust is completely seamless from the end-user’s point of view, as transmission-daemon can directly take over the already existing configuration files etc. from Fragments 1.
The implementation
I needed to create a new client that would allow me to communicate with the Transmission RPC API. This was fortunately not a huge challenge in Rust thanks to serde-json. To keep this abstraction consistent, I decided not to develop this client in-tree within the Fragments source code, but to publish it as a separate crate on crates.io: transmission-client
This crate takes care of RPC communication only, and can therefore be easily reused in other Rust apps. However, from a Fragments perspective, it would be beneficial if I would be able to use the Transmission API using the GObject type system. So I decided to develop a second crate: transmission-gobject. This wraps the API of the first crate into gtk-rs gobjects. This has the advantage that I can easily embed the transmission data in the Fragments interface, because everything is available as a object with properties, and models. I could therefore concentrate on the pure application in Fragments and didn’t have to worry about technical aspects of the BitTorrent backend.
To visualize the whole thing:
When starting Fragments, the transmission-daemon process also gets started automatically in the background.
Fragments 2.0
Due to the strict abstraction on the network level, there is a big advantage: It does not matter if Fragments connects to its “own” transmission-daemon, or if it connects to a remote transmission server. Likewise, Fragments can be used to remotely control another Fragments session.
For example, I have Transmission installed on my Synology NAS, and use it as a “download server”. I can now connect to it directly from within Fragments:
It is also possible to switch between the individual “connections” directly within the app:
Of course there are a lot of other new features:
A new torrent dialog window
Torrent rows have context menus now to access important actions more quickly
Session statistics
The magnet link of already added torrents can now be copied to the clipboard
Completely overhauled preferences with more options like setting a separate path for incomplete torrents, queue management, behavior when new torrents are added and much more granular network configuration with the possibility to test the connection
Fragments 2.0 can be downloaded and installed from Flathub now!
Thanks
I would like to thank Maximiliano and Chris, both helped me a lot with the Rust + GTK4 port, and Tobias who helped me with the updated design!
(I nearly went with clutterectomy, but that would be doing our old servant project a disservice.)
Yesterday, I finally merged the work-in-progress branch porting totem to GStreamer's GTK GL sink widget, undoing a lot of the work done in 2011 and 2014 to port the video widget and then to finally make use of its features.
But GTK has been modernised (in GTK3 but in GTK4 even more so), GStreamer grew a collection of GL plugins, Wayland and VA-API matured and clutter (and its siblings clutter-gtk, and clutter-gst) didn't get the resources they needed to follow.
A screenshot with practically no changes, as expected
The list of bug fixes and enhancements is substantial:
Makes some files that threw shaders warnings playable
Fixes resize lag for the widgets embedded in the video widget
Fixes interactions with widgets on some HDR capable systems, or even widgets disappearing sometimes (!)
Gets rid of the floating blank windows under Wayland
Should help with tearing, although that's highly dependent on the system
Hi-DPI support
Hardware acceleration (through libva)
Until the port to GTK4, we expect a overall drop in performance on systems where there's no VA-API support, and the GTK4 port should bring it to par with the fastest of players available for GNOME.
You can install a Preview version right now by running:
Some of the first abstractions we made when creating GNOME Builder are now available to everyone in GObject!
In particular, writing Text Editors requires tracking lots of information and changes from various sources. Sometimes those changes come from 2nd-degree objects via the object you really care about.
For example, with a GtkTextView that might mean tracking changes to a GtkTextBuffer, GtkTextTagTable, or many other application-specific accessory objects through the form of signals and properties.
To make that easier, we now have GSignalGroup and GBindingGroup merged directly into GObject. At their core, they allow you to treat a series of signals or bindings as a group and connect/disconnect them as a group. Furthermore, you can use g_object_bind_property() to bind the target instance to the binding/signal group removing even more code from your application. More than likely you’ll be better about supporting how things can change out from under you too.
In the process of upstreaming these objects, we did a bit of hardening, API cleanup, and thread-safety guarantees.
There was an article on Open for Everyone today about Nobara, a Fedora-based distribution optimized for gaming. So I have no beef with Tomas Crider or any other creator/maintainer of a distribution targeting a specific use case. In fact they are usually trying to solve or work around real problems and make things easier for people. That said I have for years felt that the need for these things is a failing in itself and it has been a goal for me in the context of Fedora Workstation to figure out what we can do to remove the need for ‘usecase distros’. So I thought it would be of interest if I talk a bit about how I been viewing these things and the concrete efforts we taken to reduce the need for usecase oriented distributions. It is worth noting that the usecase distributions have of course proven useful for this too, in the sense that they to some degree also function as a very detailed ‘bug report’ for why the general case OS is not enough.
Before I start, you might say, but isn’t Fedora Workstation as usecase OS too? You often talk about having a developer focus? Yes, developers are something we care deeply about, but for instance that doesn’t mean we pre-install 50 IDEs in Fedora Workstation. Fedora Workstation should be a great general purpose OS out of the box and then we should have tools like GNOME Software and Toolbx available to let you quickly and easily tweak it into your ideal development system. But at the same time by being a general purpose OS at heart, it should be equally easy to install Steam and Lutris to start gaming or install Carla and Ardour to start doing audio production. Or install OBS Studio to do video streaming.
Looking back over the years one of the first conclusions I drew from looking at all the usecase distributions out there was that they often where mostly the standard distro, but with a carefully procured list of pre-installed software, for instance the old Fedora game spin was exactly that, a copy of Fedora with a lot of games pre-installed. So why was this valuable to people? For those of us who have been around for a while we remember that the average linux ‘app store’ was a very basic GUI which listed available software by name (usually quite cryptic names) and at best with a small icon. There was almost no other metadata available and search functionality was limited at best. So finding software was not simple, at it was usually more of a ‘search the internet and if you find something interesting see if its packaged for your distro’. So the usecase distros who focused on having procured pre-installed software, be that games, or pro-audio software or graphics tools ot whatever was their focus was basically responding to the fact that finding software was non-trivial and a lot of people maybe missed out on software that could be useful to them since it they simply never learned about its existence.
So when we kicked of the creation of GNOME Software one of the big focuses early on was to create a system for providing good metadata and displaying that metadata in a useful manner. So as an end user the most obvious change was of course the more rich UI of GNOME Software, but maybe just as important was the creation of AppStream, which was a specification for how applications to ship with metadata to allow GNOME Software and others to display much more in-depth information about the application and provide screenshots and so on.
So I do believe that between working on a better ‘App Store’ story for linux between the work on GNOME Software as the actual UI, but also by working with many stakeholders in the Linux ecosystem to define metadata standards like AppStream we made software a lot more discoverable on Linux and thus reduced the need for pre-loading significantly. This work also provided an important baseline for things like Flathub to thrive, as it then had a clear way to provide metadata about the applications it hosts.
We do continue to polish that user experience on an ongoing basis, but I do feel we reduced the need to pre-load a ton of software very significantly already with this.
Of course another aspect of this is application availability, which is why we worked to ensure things like Steam is available in GNOME Software on Fedora Workstation, and which we have now expanded on by starting to include more and more software listings from Flathub. These things makes it easy for our users to find the software they want, but at the same time we are still staying true to our mission of only shipping free software by default in Fedora.
The second major reason for usecase distributions have been that the generic version of the OS didn’t really have the right settings or setup to handle an important usecase. I think pro-audio is the best example of this where usecase distros like Fedora Jam or Ubuntu Studio popped up. The pre-install a lot of relevant software was definitely part of their DNA too, but there was also other issues involved, like the need for a special audio setup with JACK and often also kernel real-time patches applied. When we decided to include Pro-audio support in PipeWire resolving these issues was a big part of it. I strongly believe that we should be able to provide a simple and good out-of-the box experience for musicians and audio engineers on Linux without needing the OS to be specifically configured for the task. The strong and positive response we gotten from the Pro-audio community for PipeWire I believe points to that we are moving in the right direction there. Not claiming things are 100% yet, but we feel very confident that we will get there with PipeWire and make the Pro-Audio folks full fledged members of the Fedora WS community. Interestingly we also spent quite a bit of time trying to ensure the pro-audio tools in Fedora has proper AppStream metadata so that they would appear in GNOME Software as part of this. One area there where we are still looking at is the real time kernel stuff, our current take is that we do believe the remaining unmerged patches are not strictly needed anymore, as most of the important stuff has already been merged, but we are monitoring it as we keep developing and benchmarking PipeWire for the Pro-Audio usecase.
Another reason that I often saw that drove the creation of a usecase distribution is special hardware support, and not necessarily that special hardware, the NVidia driver for instance has triggered a lot of these attempts. The NVidia driver is challenging on a lot of levels and has been something we have been constantly working on. There was technical issues for instance, like the NVidia driver and Mesa fighting over who owned the OpenGL.so implementation, which we fixed by the introduction glvnd a few years ago. But for a distro like Fedora that also cares deeply about free and open source software it also provided us with a lot of philosophical challenges. We had to answer the question of how could we on one side make sure our users had easy access to the driver without abandoning our principle around Fedora only shipping free software of out the box? I think we found a good compromise today where the NVidia driver is available in Fedora Workstation for easy install through GNOME Software, but at the same time default to Nouveau of the box. That said this is a part of the story where we are still hard at work to improve things further and while I am not at liberty to mention any details I think I can at least mention that we are meeting with our engineering counterparts at NVidia on almost a weekly basis to discuss how to improve things, not just for graphics, but around compute and other shared areas of interest. The most recent public result of that collaboration was of course the XWayland support in recent NVidia drivers, but I promise you that this is something we keep focusing on and I expect that we will be able to share more cool news and important progress over the course of the year, both for users of the NVidia binary driver and for users of Nouveau.
What are we still looking at in terms of addressing issues like this? Well one thing we are talking about is if there is value/need for a facility to install specific software based on hardware or software. For instance if we detect a high end gaming mouse connected to your system should we install Piper/ratbag or at least make GNOME Software suggest it? And if we detect that you installed Lutris and Steam are there other tools we should recommend you install, like the gamemode GNOME Shell extenion? It is a somewhat hard question to answer, which is why we are still pondering it, on one side it seems like a nice addition, but such connections would mean that we need to have a big database we constantly maintain which isn’t trivial and also having something running on your system to lets say check for those high end mice do add a little overhead that might be a waste for many users.
Another area that we are looking at is the issue of codecs. We did a big effort a couple of years ago and got AC3, mp3, AAC and mpeg2 video cleared for inclusion, and also got the OpenH264 implementation from Cisco made available. That solved a lot of issues, but today with so many more getting into media creation I believe we need to take another stab at it and for instance try to get reliable hardware accelerated encoding and decoding on video. I am not ready to announce anything, but we got a few ideas and leads we are looking at for how to move the needle there in a significant way.
So to summarize, I am not criticizing anyone for putting together what I call usecase distros, but at the same time I really want to get to a point where they are rarely needed, because we should be able to cater to most needs within the context of a general purpose Linux operating system. That said I do appreciate the effort of these distro makers both in terms of trying to help users have a better experience on linux and in indirectly helping us showcase both potential solutions or highlight the major pain points that still needs addressing in a general purpose Linux desktop operating system.
It’s been a while since I last blogged about the state of Fractal-next. Even though I’m not great at writing updates we’ve been making steady and significant progress on the code front. Before we dive into our progress I want to say thank you to all contributors, and especially Kévin Commaille. Keep up the good work .
Encryption
Fractal-next now has support for sending and receiving room messages and allows people to verify their newly logged-in session and other users via cross-signing.
Thanks to the matrix-rust-sdk we got room encryption, especially the key management relatively easily. Nevertheless, we had to to integrate the SDK into Fractal and figure out a user experience that would work well with our design patterns and integrate with the GNOME desktop.
I spent quite a bit of time with Tobias, our designer, figuring out a design for session and user verification. Most of that has landed now, and though it still needs more polish, it work pretty well already.
One of the bigger differences between Element and Fractal-next is that we require users to always verify their new session, because making encryption “optional” on login means you end up with a confusing, half-functional session.
The user needs to verify the newly logged in session.
To fully support Matrix E2E encryption we will still need to implement the key backup system (which is not yet supported by matrix-rust-sdk). Currently we also don’t have a way to turn on encryption for a room. And of course we also still need lot more testing to make sure everything works.
Session management
Session/device managment has been in Fractal-next for a while now, allowing people to log out of other sessions and check if other sessions are verified.
The user can terminate logged in sessions.
Many new features
Fractal-next is currently in a bit of an inbetween state, where we don’t quite have all features from the old GTK3 version yet, but at the same time we have some very advanced new features we never managed to implement there.
A good example of this are reactions added by Kévin. Also, we’ve had multi-account support since last summer, but still no support for logging out .
The room history with a reaction.
There are also so many other things being implemented in record time that I’m not always sure what we have already added and what not (Thankfully we have an issue tracker ).
To mention a few recent additions:
Moving rooms between categories via drag&drop as well as via a context menu.
The most important part of the room details
Switching between versions of rooms after upgrades
Media viewer for media in rooms
Rich replies
Updates about the NLnet Grant
If you remember my work on Fractal-next was sponsored by NLnet. The initial grant was to add end-to-end encryption to Fractal, which then lead to the rewrite and Fractal-next. Luckily they accepted to sponsor more work. Without their support it wouldn’t have been possible for me to spend so much time on this project.
I still need to finish some things up before I can wrap up the grant project, which I really hope to do it within the next few weeks. I have also been talking to NLnet to get another extension to keep working on Fractal-next full-time a bit longer, to get everything in shape for a first release later this year.
The following items are part of the grant project and still missing:
Finish the message store/cache for the SDK:
This was much more complicated then anticipated, since Matrix doesn’t supported a persistent local copy of a room’s timeline, because the Event Graph can change due to federation.
The grant foresees an Accessibility Audit and Security Audit:
These wouldn’t have made sense so far since the app isn’t complete enough yet, so this is still outstanding.
At FOSDEM 2022
Don’t miss my talk about Fractal-next at FOSDEM 2022. It will be part of the matrix-rust-sdk talk.
Took babes to school, CS3 interspersed with sales call
with Eloy; catch-up with Gokay. C'bra quarterly mgmt call much
of the afternoon - caught up with admin in parallel.
I switched to Fedora silverblue not too long ago and was quite surprised how everything works out of the box. One day we got a question about CMake and the backend we use for our CMake plugin. This is the start of a long adventure:
Why is GLFW not resolving correct?
The demo project i got my hands on was some example code of the GLFW library (a OpenGL game library). I spun up my podman development container and installed the library.
toolbox enter
sudo dnf install glfw-devel
I thought this should work. Then i realized that our clang machinery to resolve symbols, validate includes, hover provider and diagnostic provider is acting weird. Everything is red squiggled and nothing works. I wondered because my experience was smooth all the time with toolbox/podman.
The fool who stays inside
I never used anything relevant from outside of my own universe. I developed on librest and there was everything working ootb. Of course all libraries i use there are available in the builder flatpak and that was the reason in never had any problems. I just got wrong informations from a totally different development environment.
How does Builder resolve symbols?
Builder has an own little clang server. When Builder starts we also start gnome-builder-clang which acts as our “language server”. Technology-wise its different but the memory footprint is low and its fast. So it works for us.
By default this server has only access to the GNOME Builder flatpak environment (if Builder flatpak, native is different). So it will provide everything from there. In order to access the host we translate files (like includes etc.) to /var/host/ so we can also escape the flatpak environment (this is btw a reason we probably never can be sandboxed). In case of Fedora Silverblue both options are not enough. My host is immutable and does not even contain a compiler or any development files. I need access to podmans environments.
Enter the pod
Podman relies on techniques from LXC. So a running container is initially based on an image which gets mutable layers on top. So we get a filesystem with all the changes in there.
In order to find now the file (for example the header file of that library i installed GLFW/glfw3.h) i have to find my container, reconstruct the layer hierarchy and search from the top layer till the image layer for my header. When i have found it i can build a host-compatible path and feed this into the clang machinery.
The actual change to Builder’s code is particular small but the gist to understand how i can build correct translations was huge. I want to thank Christian Hergert for his help. He had a similar problem with debug symbols in sysprof and his preliminary work made the resolution of that problem way easier.
This year I've started with something that I wanted to do since the first COVID
lockdown, but never did. So as a first year resolution I decided to start
streaming and I created my Twitch channel Abentogil.
I've been thinking about streaming since lockdown, when a group of Spanish
people created a nice initiative to teach kids how to code and other tech
stuff. I never participated on that initiative, but it was the seed of this.
This year I've seen other GNOME streamers doing live coding, like ebassi
and Georges and, at the end, I pluck up the courage to start.
The plan
I've started with one our at the end of my day, so I'm trying to stream from
Monday to Thursday from 20:00 to 21:00 (CET).
This routing also will help me to spend more time in free software development
regularly, so not just on weekends or holidays, but a bit of work everyday.
Right now I've started working on my own projects, like Timetrack and
Loop. I've fixed some issues that I had with Gtk4 in Timetrack and I've
started to work on the Loop app to add a MIDI keyboard.
The other day I discovered the Music Grid app idea in the gitlab and it's
related with the MIDI implementation I've been working on, so the next thing
that I'll do on my streams is to create this music grid widget and add it to
the Loop app, to have a nice Music creation App.
The language: Live coding in Spanish
I've decided to do the streaming mainly in Spanish. The main reason to do that
is because now you can find documentation and a lot of videos in English, but
for people that doesn't master the English language, it's harder to follow this
content and even harder to participate, to ask or say something.
Spanish is also my main language, and the idea is not just create tutorials or
something like that, this is just for fun, and if I'm able to create a small
community or influence someone, I want to show that the language is not a
unbreakable barrier.
I want to make this for the Spanish community, but that doesn't mean that for
some streams I cannot talk in English, all depends on the audience, of course,
if a non Spanish speaker comes and ask something, I'll answer in English and
try to do multilingual stream.
The International English is the language to use in Free Software, but it's
really important to do not convert that in a barrier, because there are a lot
of different communities and people that don't know the language and the first
contact with something new is always better in your main language. Everything
is easier with help from people that's near to your cultural background.
The future
Right now I'm working on Loop and every stream is similar, live coding on this
Gtk4 music APP, but in the future I'll do different streams, doing different
things on each week day. These are the current ideas that could be a day on my
stream:
Maintenance day: Work on my apps, code review, fixes, releases, and
development.
GNOME Love day: Give some love to the GNOME project, look for simple bugs to
solve in different projects, help with translations, initiatives, and other
possible one hour task to give some love to the project in general.
Learning day: Pick some technology and learn by doing, for example, I
can explore new programming languages writing a simple app, learn about
Linux writing a driver, learn how to animate with blender, anything new to
play and discover.
Newcomers day: Create simple tutorial or introduction to some technology,
How to write a GNOME Shell extension, how to create a Gtk4 app in python,
teach to code from zero, etc.
This is just a list of ideas, if I discover any other interesting use of this
time and stream, I can do that. The final goal of this is to have fun, and if
someone learns something in the journey, that's even better.
I'll also upload any interesting stream to youtube, so the good content
could be viewed on demand.
So if you like this, don't hesitate to view some of the streams and say "Hola":
The GNOME Foundation was supported during 2020-2021 by a grant from Endless Network which funded the Community Engagement Challenge, strategy consultancy with the board, and a contribution towards our general running costs. At the end of last year we had a portion of this grant remaining, and after the success of our work in previous years directly funding developer and infrastructure work on GTK and Flathub, we wanted to see whether we could use these funds to invest in GNOME and the wider Linux desktop platform.
We’re very pleased to announce that we got approval to launch three parallel contractor engagements, which started over the past few weeks. These projects aim to improve our developer experience, make more applications available on the GNOME platform, and move towards equitable and sustainable revenue models for developers within our ecosystem. Thanks again to Endless Network for their support on these initiatives.
Flathub – Verified apps, donations and subscriptions (Codethink and James Westman)
This project is described in detail on the Flathub Discourse but goal is to add a process to verify first-party apps on Flathub (ie uploaded by a developer or an authorised representative) and then make it possible for those developers to collect donations or subscriptions from users of their applications. We also plan to publish a separate repository that contains only these verified first-party uploads (without any of the community contributed applications), as well as providing a repository with only free and open source applications, allowing users to choose what they are comfortable installing and running on their system.
Creating the user and developer login system to manage your apps will also set us up well for future enhancements, such managing tokens for direct binary uploads (eg from a CI/CD system hosted elsewhere, as is already done with Mozilla Firefox and OBS) and making it easier to publish apps from systems such as Electron which can be hard to use within a flatpak-builder sandbox. For updates on this project you can follow the Discourse thread, check out the work board on GitHub or join us on Matrix.
PWAs – Integrating Progressive Web Apps in GNOME (Phaedrus Leeds)
While everyone agrees that native applications can provide the best experience on the GNOME desktop, the web platform, and particularly PWAs (Progressive Web Apps) which are designed to be downloadable as apps and offer offline functionality, makes it possible for us to offer equivalent experiences to other platforms for app publishers who have not specifically targeted GNOME. This allows us to attract and retain users by giving them the choice of using applications from a wider range of publishers than are currently directly targeting the Linux desktop.
The first phase of the GNOME PWA project involves adding back support to Software for web apps backed by GNOME Web, and making this possible when Web is packaged as a Flatpak. So far some preparatory pull requests have been merged in Web and libportal to enable this work, and development is ongoing to get the feature branches ready for review.
Discussions are also in progress with the Design team on how best to display the web apps in Software and on the user interface for web apps installed from a browser. There has also been discussion among various stakeholders about what web apps should be included as available with Software, and how they can provide supplemental value to users without taking priority over apps native to GNOME.
Finally, technical discussion is ongoing in the portal issue tracker to ensure that the implementation of a new dynamic launcher portal meets all security and robustness requirements, and is potentially useful not just to GNOME Web but Chromium and any other app that may want to install desktop launchers. Adding support for the launcher portal in upstream Chromium, to facilitate Chromium-based browsers packaged as a Flatpak, and adding support for Chromium-based web apps in Software are stretch goals for the project should time permit.
GTK4 / Adwaita – To support the adoption of Gtk4 by the community (Emmanuele Bassi)
With the release of GTK4 and renewed interest in GTK as a toolkit, we want to continue improving the developer experience and ease of use of GTK and ensure we have a complete and competitive offering for developers considering using our platform. This involves identifying missing functionality or UI elements that applications need to move to GTK4, as well as informing the community about the new widgets and functionality available.
We have been working on documentation and bug fixes for GTK in preparation for the GNOME 42 release and have also started looking at the missing widgets and API in Libadwaita, in preparation for the next release. The next steps are to work with the Design team and the Libadwaita maintainers and identify and implement missing widgets that did not make the cut for the 1.0 release.
In the meantime, we have also worked on writing a beginners tutorial for the GNOME developers documentation, including GTK and Libadwaita widgets so that newcomers to the platform can easily move between the Interface Guidelines and the API references of various libraries. To increase the outreach of the effort, Emmanuele has been streaming it on Twitch, and published the VOD on YouTube as well.
Now to the BIG question, How did I get into open source? I read about Google Summer of Code and Outreachy internships as a part of my research. That’s when I came across Priyanka Saggu. She was a previous Outreachy intern with GNOME. She guided me on how to get started with open source. OneContinue reading "Aditi’s Open Source Journey"
Happy 2022 everyone! Hope it was a safe one. I managed to travel a bit and visit my family while somehow dodging Omicron each step of the way. I guess you cant ask for much more than that.
I am keeping busy at work integrating BuildStream with a rather large, tricky set of components, Makefiles and a custom dependency management system. I am appreciating how much flexibility BuildStream provides. As an example, some internal tools expect builds to happen at a certain path. BuildStream makes it easy to customize the build path by adding this stanza to the .bst file:
variables:
build-root: /magic/path
I am also experimenting with committing whole build trees as artifacts, as a way to distribute tests which are designed to run within a build tree. I think this will be easier in Bst 2.x, but it’s not impossible in Bst 1.6 either.
Besides that I have been mostly making music, stay tuned for a new Vladimir Chicken EP in the near future.
Compromising an OS without it being detectable is hard. Modern operating systems support the imposition of a security policy or the launch of some sort of monitoring agent sufficient early in boot that even if you compromise the OS, you're probably going to have left some sort of detectable trace[1]. You can avoid this by attacking the lower layers - if you compromise the bootloader then it can just hotpatch a backdoor into the kernel before executing it, for instance.
This is avoided via one of two mechanisms. Measured boot (such as TPM-based Trusted Boot) makes a tamper-proof cryptographic record of what the system booted, with each component in turn creating a measurement of the next component in the boot chain. If a component is tampered with, its measurement will be different. This can be used to either prevent the release of a cryptographic secret if the boot chain is modified (for instance, using the TPM to encrypt the disk encryption key), or can be used to attest the boot state to another device which can tell you whether you're safe or not. The other approach is verified boot (such as UEFI Secure Boot), where each component in the boot chain verifies the next component before executing it. If the verification fails, execution halts.
In both cases, each component in the boot chain measures and/or verifies the next. But something needs to be the first link in this chain, and traditionally this was the system firmware. Which means you could tamper with the system firmware and subvert the entire process - either have the firmware patch the bootloader in RAM after measuring or verifying it, or just load a modified bootloader and lie about the measurements or ignore the verification. Attackers had already been targeting the firmware (Hacking Team had something along these lines, although this was pre-secure boot so just dropped a rootkit into the OS), and given a well-implemented measured and verified boot chain, the firmware becomes an even more attractive target.
Intel's Boot Guard and AMD's Platform Secure Boot attempt to solve this problem by moving the validation of the core system firmware to an (approximately) immutable environment. Intel's solution involves the Management Engine, a separate x86 core integrated into the motherboard chipset. The ME's boot ROM verifies a signature on its firmware before executing it, and once the ME is up it verifies that the system firmware's bootblock is signed using a public key that corresponds to a hash blown into one-time programmable fuses in the chipset. What happens next depends on policy - it can either prevent the system from booting, allow the system to boot to recover the firmware but automatically shut it down after a while, or flag the failure but allow the system to boot anyway. Most policies will also involve a measurement of the bootblock being pushed into the TPM.
AMD's Platform Secure Boot is slightly different. Rather than the root of trust living in the motherboard chipset, it's in AMD's Platform Security Processor which is incorporated directly onto the CPU die. Similar to Boot Guard, the PSP has ROM that verifies the PSP's own firmware, and then that firmware verifies the system firmware signature against a set of blown fuses in the CPU. If that fails, system boot is halted. I'm having trouble finding decent technical documentation about PSB, and what I have found doesn't mention measuring anything into the TPM - if this is the case, PSB only implements verified boot, not measured boot.
What's the practical upshot of this? The first is that you can't replace the system firmware with anything that doesn't have a valid signature, which effectively means you're locked into firmware the vendor chooses to sign. This prevents replacing the system firmware with either a replacement implementation (such as Coreboot) or a modified version of the original implementation (such as firmware that disables locking of CPU functionality or removes hardware allowlists). In this respect, enforcing system firmware verification works against the user rather than benefiting them. Of course, it also prevents an attacker from doing the same thing, but while this is a real threat to some users, I think it's hard to say that it's a realistic threat for most users.
The problem is that vendors are shipping with Boot Guard and (increasingly) PSB enabled by default. In the AMD case this causes another problem - because the fuses are in the CPU itself, a CPU that's had PSB enabled is no longer compatible with any motherboards running firmware that wasn't signed with the same key. If a user wants to upgrade their system's CPU, they're effectively unable to sell the old one. But in both scenarios, the user's ability to control what their system is running is reduced.
As I said, the threat that these technologies seek to protect against is real. If you're a large company that handles a lot of sensitive data, you should probably worry about it. If you're a journalist or an activist dealing with governments that have a track record of targeting people like you, it should probably be part of your threat model. But otherwise, the probability of you being hit by a purely userland attack is so ludicrously high compared to you being targeted this way that it's just not a big deal.
I think there's a more reasonable tradeoff than where we've ended up. Tying things like disk encryption secrets to TPM state means that if the system firmware is measured into the TPM prior to being executed, we can at least detect that the firmware has been tampered with. In this case nothing prevents the firmware being modified, there's just a record in your TPM that it's no longer the same as it was when you encrypted the secret. So, here's what I'd suggest:
1) The default behaviour of technologies like Boot Guard or PSB should be to measure the firmware signing key and whether the firmware has a valid signature into PCR 7 (the TPM register that is also used to record which UEFI Secure Boot signing key is used to verify the bootloader). 2) If the PCR 7 value changes, the disk encryption key release will be blocked, and the user will be redirected to a key recovery process. This should include remote attestation, allowing the user to be informed that their firmware signing situation has changed. 3) Tooling should be provided to switch the policy from merely measuring to verifying, and users at meaningful risk of firmware-based attacks should be encouraged to make use of this tooling
This would allow users to replace their system firmware at will, at the cost of having to re-seal their disk encryption keys against the new TPM measurements. It would provide enough information that, in the (unlikely for most users) scenario that their firmware has actually been modified without their knowledge, they can identify that. And it would allow users who are at high risk to switch to a higher security state, and for hardware that is explicitly intended to be resilient against attacks to have different defaults.
This is frustratingly close to possible with Boot Guard, but I don't think it's quite there. Before you've blown the Boot Guard fuses, the Boot Guard policy can be read out of flash. This means that you can drop a Boot Guard configuration into flash telling the ME to measure the firmware but not prevent it from running. But there are two problems remaining:
1) The measurement is made into PCR 0, and PCR 0 changes every time your firmware is updated. That makes it a bad default for sealing encryption keys. 2) It doesn't look like the policy is measured before being enforced. This means that an attacker can simply reflash modified firmware with a policy that disables measurement and then make a fake measurement that makes it look like the firmware is ok.
Fixing this seems simple enough - the Boot Guard policy should always be measured, and measurements of the policy and the signing key should be made into a PCR other than PCR 0. If an attacker modified the policy, the PCR value would change. If an attacker modified the firmware without modifying the policy, the PCR value would also change. People who are at high risk would run an app that would blow the Boot Guard policy into fuses rather than just relying on the copy in flash, and enable verification as well as measurement. Now if an attacker tampers with the firmware, the system simply refuses to boot and the attacker doesn't get anything.
Things are harder on the AMD side. I can't find any indication that PSB supports measuring the firmware at all, which obviously makes this approach impossible. I'm somewhat surprised by that, and so wouldn't be surprised if it does do a measurement somewhere. If it doesn't, there's a rather more significant problem - if a system has a socketed CPU, and someone has sufficient physical access to replace the firmware, they can just swap out the CPU as well with one that doesn't have PSB enabled. Under normal circumstances the system firmware can detect this and prompt the user, but given that the attacker has just replaced the firmware we can assume that they'd do so with firmware that doesn't decide to tell the user what just happened. In the absence of better documentation, it's extremely hard to say that PSB actually provides meaningful security benefits.
So, overall: I think Boot Guard protects against a real-world attack that matters to a small but important set of targets. I think most of its benefits could be provided in a way that still gave users control over their system firmware, while also permitting high-risk targets to opt-in to stronger guarantees. Based on what's publicly documented about PSB, it's hard to say that it provides real-world security benefits for anyone at present. In both cases, what's actually shipping reduces the control people have over their systems, and should be considered user-hostile.
[1] Assuming that someone's both turning this on and actually looking at the data produced







































 .
.
 ) attempts to implement this.
) attempts to implement this.
 . For the long term, I would love to port this application to GTK4 and Libadwaita.
. For the long term, I would love to port this application to GTK4 and Libadwaita.




















 A screenshot with practically no changes, as expected
A screenshot with practically no changes, as expected
 .
.



 ).
).