Summary
The code pattern shows how to deploy a microservice-based back end in OpenShift 4.3, with examples in Red Hat® OpenShift® on IBM Cloud™. To simulate a series of mobile views, the examples show how to deploy a Node.js-based service.
Description
As people become more aware of data and concerned about their online privacy, regulations around the world have started requiring software projects to think about how customers’ data is handled. This pattern deploys a set of microservices to act as a back end for a mobile bank application, such as those often used by businesses who want to better understand how people use their services by collecting data. Although inspired by regulations such GDPR (Europe’s general data protection regulations), as this is not a real public facing application, we implement a few data privacy features as a way of demonstrating how one might go about building a privacy-focused back end in OpenShift 4.
The GDPR standard defines requirements around what operations need to be available to users (“subjects”). However, GDPR is technology neutral, so it ends up being the responsibility of the implementors to build the architecture that implements the requirements. In addition, with the move toward microservices architectures and containerization, technology such as service mesh may be useful in the context of a data privacy service.
Flow
The following diagram shows the architecture flow for user authentication.
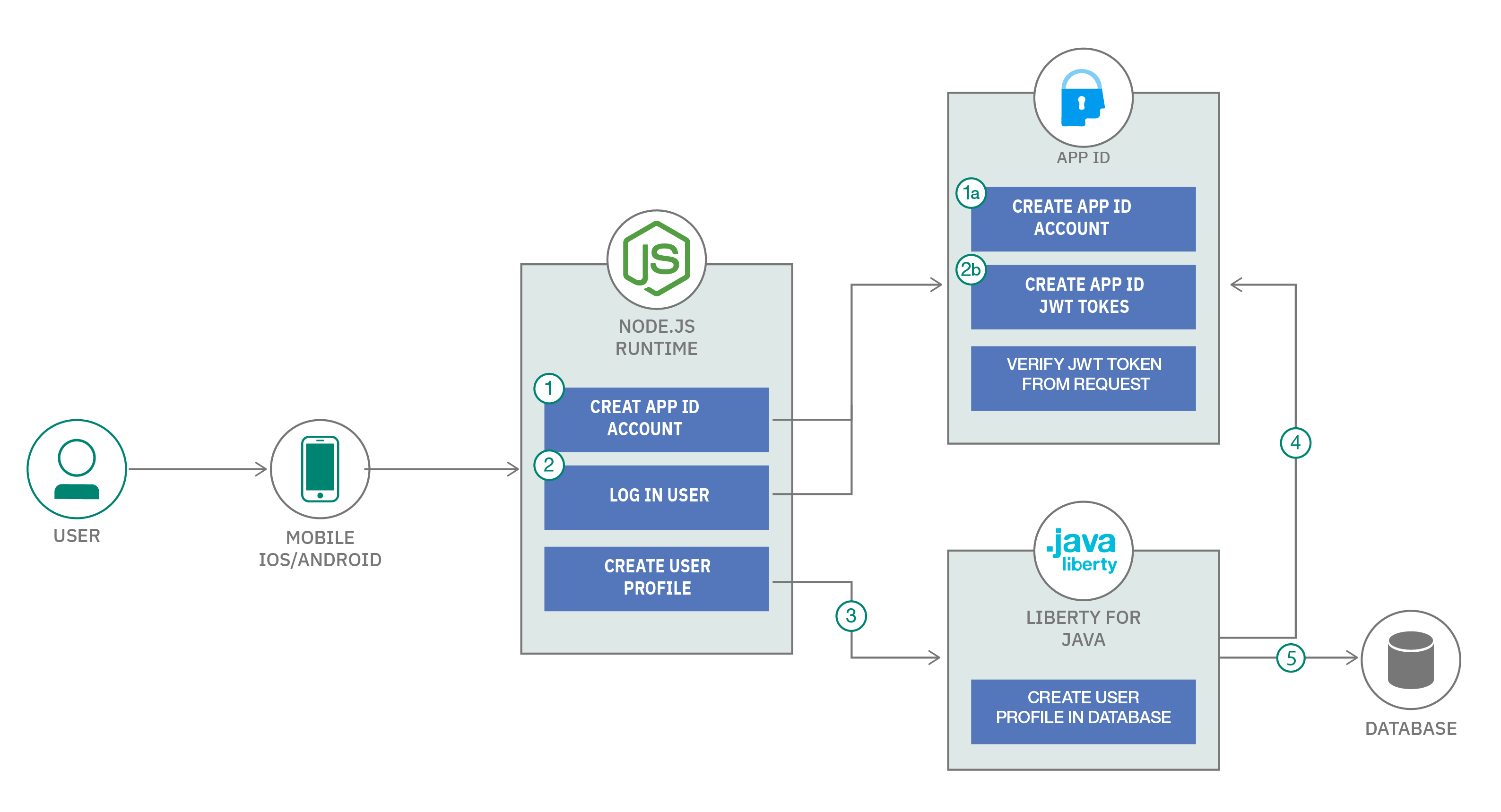
- The user creates an account using the mobile app simulator. This hits an API from the Node.js server. The Node.js server then hits an API from the App ID service that would create the user’s account in its own cloud directory.
- The mobile app simulator then logs in the user after account creation. The App ID service then creates valid access tokens and ID tokens for the user. The mobile app stores these tokens for later use in authentication.
- Using the access token from the previous step, the mobile app can now successfully call the protected APIs in the Liberty microservice. The mobile app calls the API with the access token in the authorization header to create the user profile in the database.
- The Liberty service is integrated with the App ID instance. This verifies the access token in the authorization header from the request.
- When the token is valid, the user profile is created in the database. The access token contains the user ID of the user that sent the request.
The Auth token flow with App ID is the identity provider and Liberty uses the token to authenticate users.
The Liberty microservices are protected APIs that require authorization headers. If the request does not have one, it will not allow the request to be processed, thus sending a 401 Unauthorized response. The microservice makes use of a managed identity provider, App ID for this authentication. This makes it easier to protect APIs and manage identity information of users.
The mobile app simulator is integrated with the App ID instance and whenever a user logs in, the app receives access tokens and stores it for later use in requests to the protected APIs. The tokens expire in an hour by default which would require users to authenticate again after expiration.
Whenever a request with a token in the authorization header is sent, the Liberty microservice uses the App ID integration to make sure that the token is valid. Then it continues to process the request. The liberty microservice also makes use of the subject ID or user ID in the token to identify which user is making the request. For example, when a user asks for his number of points earned, it needs to pull the right profile from the database. This is where the user ID in the token payload can be made use of.
Instructions
To try out this code pattern, see the detailed technical steps in the README.md file.
- Set up an OpenShift 4.3 cluster.
- Set up an App ID instance.
- Deploy the PostgreSQL instance and schema.
- Deploy the OpenShift Serverless Operator.
- Create Kubernetes secrets used by the microservices.
- Deploy the remaining services.