
Test automation, with product built in microservice architecture could be very situational in context of testing goals and ways to achieve them. You got an easy life if you testing a service, that is an isolated entity, which is receiving some data and providing a result of it's work in a response, by callback or through additional endpoint. In this case all you need to do is cover all the endpoints of the service, and probably learn to catch it's callbacks. However, it's not the only case. Sometimes you need to test service which isn't totally isolated, but a part of a chain of interactions. This service could send some data to other services within your infrastructure or even to third parties. This time you got plenty of additional things to bother of:
Software testers — an endangered species?

Nothing and nobody will escape oblivion. Whatever you may say, the history of mankind is a history of automation and the subsequent evolution of workers. This happened both during the first industrial revolution and during the second. The same thing happened with digital revolution. Now machine learning and artificial intelligence are being implemented everywhere. What is the future of software testing?
New features of the hybrid monitoring AIOps system Monq

In one of the previous articles, I’ve already written about the hybrid monitoring system from Monq. Almost two years have passed since then. During this time, Monq has significantly updated its functionality, a free version has appeared, and the licensing policy has been updated. If monitoring systems in your company start to get out of control, and their number rushes somewhere beyond the horizon, we suggest you take a look at Monq to take control of monitoring. Welcome under the cut.
Application performance monitoring and health metrics without APM

I have already written about AIOps and machine learning methods in working with IT incidents, about hybrid umbrella monitoring and various approaches to service management. Now I would like to share a very specific algorithm, how one can quickly get information about functioning conditions of business applications using synthetic monitoring and how to build, on this basis, the health metric of business services at no special cost. The story is based on a real case of implementing the algorithm into the IT system of one of the airlines.
Currently there are many APM systems, such as Appdynamics, Dynatrace, and others, having a UX control module inside that uses synthetic checks. And if the task is to learn about failures quicker than customers, I will tell you why all these APM systems are not needed. Also, nowadays health metrics are a fashionable feature of APM and I will show how you can build them without APM.
Run MongoDB Atlas locally for testing
What happens to your MongoDB replica set when it comes to failures like network partitioning, restarting, reconfiguration of the existing topology, etc.? This question is especially important these days because of the popularity gained by the multi-cloud model where chances of these scenarios are quite realistic.
However, is there a solution, preferably a free one, for testing such cases that would obviate the need of writing manual scripts and poring over the official documentation? As software developers, we would be better off preparing our applications in advance to survive these failures.
Agreements as Code: how to refactor IaC and save your sanity?

Before we start, I'd like to get on the same page with you. So, could you please answer? How much time will it take to:
- Create a new environment for testing?
- Update java & OS in the docker image?
- Grant access to servers?

It will take longer than you expect. I will explain why.
QA process at Miro
What do we do? We need to do preliminary preparation for each block of the development process: task decomposition, evaluation and planning, development itself, investigative testing, and release. This preparation does not consist of simply throwing old parts out of the process but of their adequate replacement, which increases quality.
In this article, I will talk in detail about our testing process at each stage of creating a new feature and also about the introduced changes that have increased the quality and speed of development.

Meet Hamstand: a smart mobile testing hub

Managing hundreds of servers for load testing: autoscaling, custom monitoring, DevOps culture
- Terraform scripts for creating and deleting a test environment;
- Ansible scripts for configuring, updating, starting servers;
- In-house Python scripts for dynamic scaling, depending on the load.
Thanks to the Terraform and Ansible scripts, all operations ranging from creating instances to starting servers are performed with only six commands:
#launch the required instances in the AWS console
ansible-playbook deploy-config.yml #update servers versions
ansible-playbook start-application.yml #start our app on these servers
ansible-playbook update-test-scenario.yml --ask-vault-pass #update the JMeter test scenario if it was changed
infrastructure-aws-cluster/jmeter_clients:~# terraform apply #create JMeter servers for creating the load
playbook start-jmeter-server-cluster.yml #start the JMeter cluster
ansible-playbook start-stress-test.yml #start the test
How to test Ansible and don't go nuts

It is the translation of my speech at DevOps-40 2020-03-18:
After the second commit, each code becomes legacy. It happens because the original ideas do not meet actual requirements for the system. It is not bad or good thing. It is the nature of infrastructure & agreements between people. Refactoring should align requirements & actual state. Let me call it Infrastructure as Code refactoring.
Reliable load testing with regards to unexpected nuances
The irony is that simultaneously with the launch of the test, we reached the limits on the production server, resulting in two-hour service downtime. This further encouraged us to move from making occasional tests to establishing an effective load testing infrastructure. By infrastructure, I mean all tools for working with load testing: tools for launching the test (manual and automatic), the cluster that creates the load, a production-like cluster, metrics and reporting services, scaling services, and the code to manage it all.
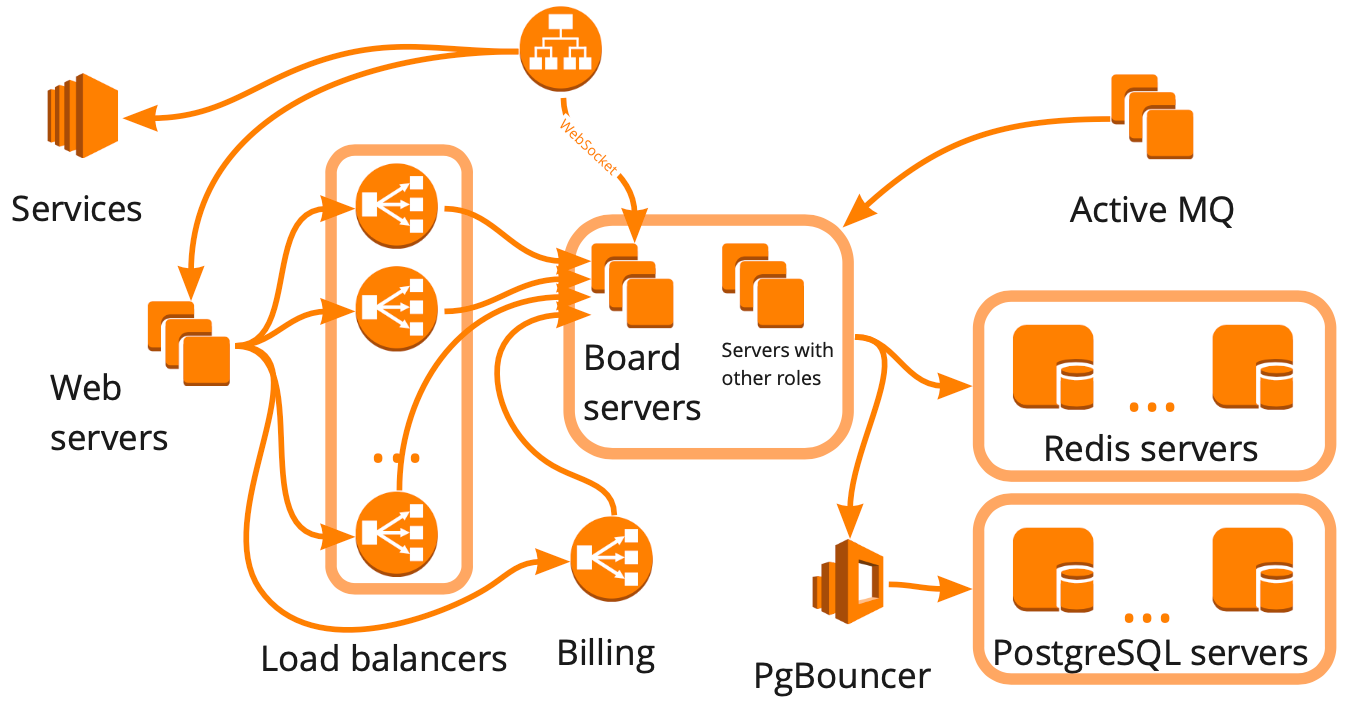
Simplified, this is what our structure looks like: a collection of different servers that somehow interact with each other, each server performing specific tasks. It seemed that to build the load testing infrastructure, it was enough for us to make this diagram, take account of all interactions, and start creating test cases for each block one by one.
This approach is right, but it would have taken many months, which was not suitable for us because of our rapid growth — over the past twelve months, we have grown from 12,000 to 100,000 simultaneously active online users. Also, we didn’t know how our service infrastructure would respond to the increased load: which blocks would become the bottleneck, and which would scale linearly?
About integration tests
[Quicksort] reduces complexity on each pass of a given input. So far so good. Let's imagine example with 10 elements. How many possible permutations do we have? you are right: 10! ~= 3,6 * 10^6. So on the first pass the complexity will be reduced: 5!*5!, on the next pass it will be further reduced till 2!*3!*2!*3!… after logn times we will have 1!*1!*1!...1! = 1 possible position, and our given input is sorted. Gotcha. (attentive reader can mention about worst case scenario of quicksort, but lets discuss it someday) Coming back to our example…
About Testing
Despite of lots of benefits, tests have two fundamental problems: there is no architecture at all (quality), nobody knows what is the meaning of the quantity.
Tests have a cost. Lets imagine dialog between manager and developer:
— John, how many hours does it take to implement?
— Approximately one week: 1,5 day for task and 3,5 days to write tests
So why people write tests? Let's try to build a mental model: we delivered a component, our beta testers found a bug, we wrote tests scenario. So, next time we try to deliver the same component, we already know about bad scenario and have automation to check it. So far so good. Next, we are trying to predict future bugs by writing lot's of tests and cover bad scenarios. Next, we deliver better components, users are happy. Profit. (Despite of all pros, the solution is not scalable — with every new component we will face a reality).
Conditional coverage

Recently I had to add python3.8 for our Python linter (the strictest one in existence): wemake-python-styleguide. And during this straight-forward (at first look) task, I have found several problems with test coverage that were not solved in Python community at all.
Let's dig into it.
What does «clean code» mean in 2020?

«Clean Code» and a clean cat
There is nothing developers enjoy better than arguing about clean code: Dan Abramov, for example, has recently fueled the hype with his blog post, «Goodbye, Clean Code».
However, “clean code” per se doesn’t even have a clear definition. The main book on the subject is Clean Code, where Robert «Uncle Bob» Martin states that there are perhaps as many definitions as there are programmers. But he doesn’t walk away from the fact with a conclusion that there’s no reason to discuss clean code, rather — compare several definitions and highlight general ideas. Therefore he cites the views of several outstanding programmers on what clean code is.
So we have also become interested in what people in 2020 think of clean code. Have the views changed since the publication of the book? Do opinions vary in different IT fields (maybe backend developers perceive the idea of clean code differently from testers)?
This spring, Uncle Bob comes to St. Petersburg to give talks at our three conferences: they are about .NET development, testing and JavaScript. Therefore, we’ve asked speakers from each of those conferences to share their opinion on clean code so we could compare the opinions of the industry experts in 2020.
We've already published the results in Russian, and here's the English version. Since the topic is known to provoke discussions, feel free to give your own definition or argue about those already given!
UPD: When we posted this article, Uncle Bob had our conferences in his schedule. Unfortunately, the situation has changed. We updated this post on March 12, to avoid any misunderstanding.
Are my open-source libraries vulnerable? (2 min reading to make your life more secure)
The explosion of open source and issues related to it
The amount of open source or other third party code used in a software project is estimated as 60-90% of a codebase. Components, such as libraries, frameworks, and other software modules, almost always run with full privileges. If a vulnerable component is exploited, such an attack can facilitate serious data loss or server takeover. Applications using components with known vulnerabilities may undermine application defences and enable a range of possible attacks and impacts.

Conclusion: even if you perform constant security code reviews, you still might be vulnerable because of third-party components.
Some have tried to do this manually, but the sheer amount of work and data is growing and is time consuming, difficult, and error prone to manage. It would require several full time employees and skilled security analysts to constantly monitor all sources to stay on top.
V&V not for vendetta

Over the past six years, I have worked on developing and acceptance testing of the applications for conducting and supporting clinical trials. Applications of various sizes and complexity, big data, a huge number of visualizations and views, data warehousing, ETL, etc. The products are used by doctors, clinical trials management and people who are involved in the control and monitoring of research.
For the applications that have or can have a direct impact on the life and health of patients, a formal acceptance testing process is required. Acceptance test results along with the rest of the documentation package are submitted for audit to the FDA (Food and Drug Administration, USA). The FDA authorizes the use of the application as a tool for monitoring and conducting clinical trials. In total, my team has developed, tested and sent to the production more than thirty applications. In this article, I will briefly talk about acceptance testing and improvement of tools used for it.
Note: I do not pretend to be the ultimate truth and completely understand that most of what I write about is a Captain Obvious monologue. But I hope that the described can be useful to both the entry level and the teams that encounter this in everyday work, or at least it may make happy those who have simpler processes.
Lessons learned from testing Over 200,000 lines of Infrastructure Code

IaC (Infrastructure as Code) is a modern approach and I believe that infrastructure is code. It means that we should use the same philosophy for infrastructure as for software development. If we are talking that infrastructure is code, then we should reuse practices from development for infrastructure, i.e. unit testing, pair programming, code review. Please, keep in mind this idea while reading the article.
Handling Objections: Static Analysis Will Take up Part of Working Time
 Talking to people at conferences and in comments to articles, we face the following objection: static analysis reduces the time to detect errors, but takes up programmers' time, which negates the benefits of using it and even slows down the development process. Let's get this objection straightened out and try to show that it's groundless.
Talking to people at conferences and in comments to articles, we face the following objection: static analysis reduces the time to detect errors, but takes up programmers' time, which negates the benefits of using it and even slows down the development process. Let's get this objection straightened out and try to show that it's groundless.Configuration of the Warnings Next Generation plugin for integration with PVS-Studio

The PVS-Studio 7.04 release coincided with the release of the Warnings Next Generation 6.0.0 plugin for Jenkins. Right in this release Warnings NG Plugin added support of the PVS-Studio static code analyzer. This plugin visualizes data related to compiler warnings or other analysis tools in Jenkins. This article will cover in detail how to install and configure this plugin to use it with PVS-Studio, and will describe most of its features.