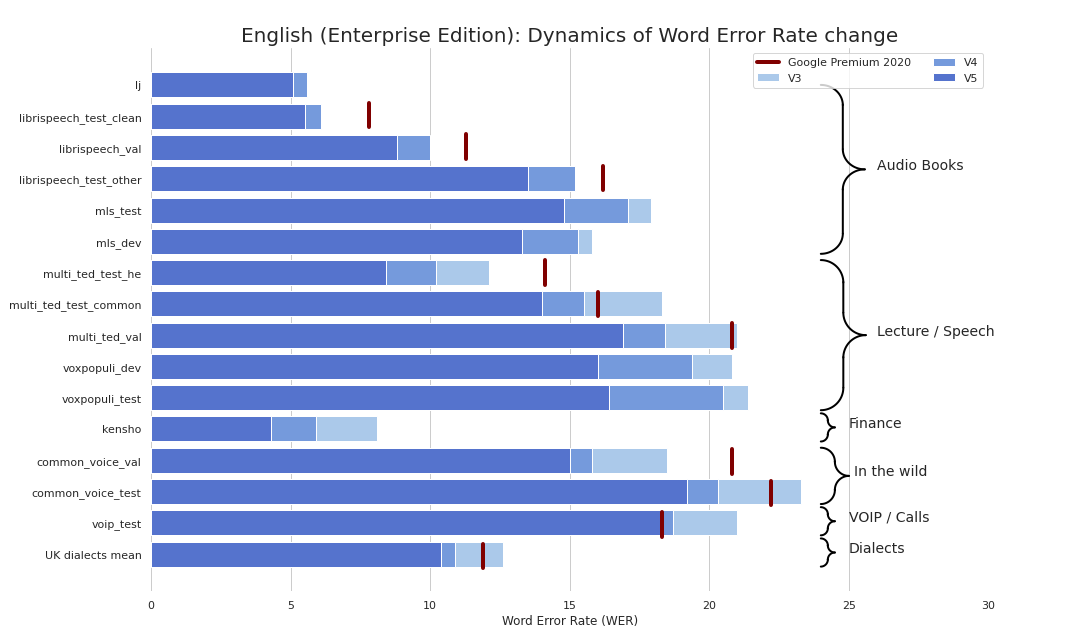
Обращали ли вы когда-нибудь внимание на то, сколько всего в кадре упускает наш мозг при просмотре фильма? Каждый раз, когда вы пересматриваете своё любимое кино, вы замечаете что-то новое.
Возьмём для примера великое – “Назад в будущее”. Главное, что захватывает в фильме, это, конечно, сюжет. Но во сколько лет на какой просмотр вы узнали, что в конце фильма магазин "Две сосны" поменял своё название на "Одинокая сосна"? Это происходит потому, что Марти сбивает дерево на ферме Пибоди, влетев в прошлое на DeLorean DMC-12. В первый раз это тяжеловато увидеть, но это важная деталь сюжета.
А помните ли вы диван, на котором так уютно сидели “Друзья” в квартире Моники и Рейчел? Наверняка, у нас всех в памяти хранится его общий вид, но когда заходишь в магазин и хочешь купить такой же, вряд ли вспомнишь всё в деталях.
В момент просмотра фильма, мы часто сфокусированы на сюжете и происходящем на переднем плане, из-за чего можем упускать детали, без которых фильм может показаться не столь продуманным.
Но не беспокойтесь. В 2021 это больше не проблема, ведь теперь есть платформа компьютерного зрения Layer, которая смотрит кино вместе с вами. От неё никаким деталям не спрятаться и не скрыться. Давайте заглянем “под капот”?